인스턴스 축소
•
숫자 감소: 속성의 수가 아닌 데이터 포인트의 수를 줄여서 데이터를 축소하는 방법

인스턴스 축소 방법
•
비모수 모델 기반 숫자 감소 방법: 히스토그램, 데이터 집계, 샘플링, 클러스터
•
모수 모델 기반 숫자 감소 방법: 전체 데이터 대신 데이터 모델을 저장
◦
예: 로그 선형 모델 또는 회귀모델
버킷을 활용한 인스턴스 축소 방법
•
데이터를 구분하는 버킷을 결정하고, 버킷에 따라 값을 할당하는 방법
•
히스토그램
버킷 생성 방법
•
동일 빈도 수 :각 버킷은 동일한 수의 데이터 샘플을 보유함
◦
각 버킷의 주파수가 거의 일정
•
동일 너비 : 각 버킷의 너비를 균일하게 설정
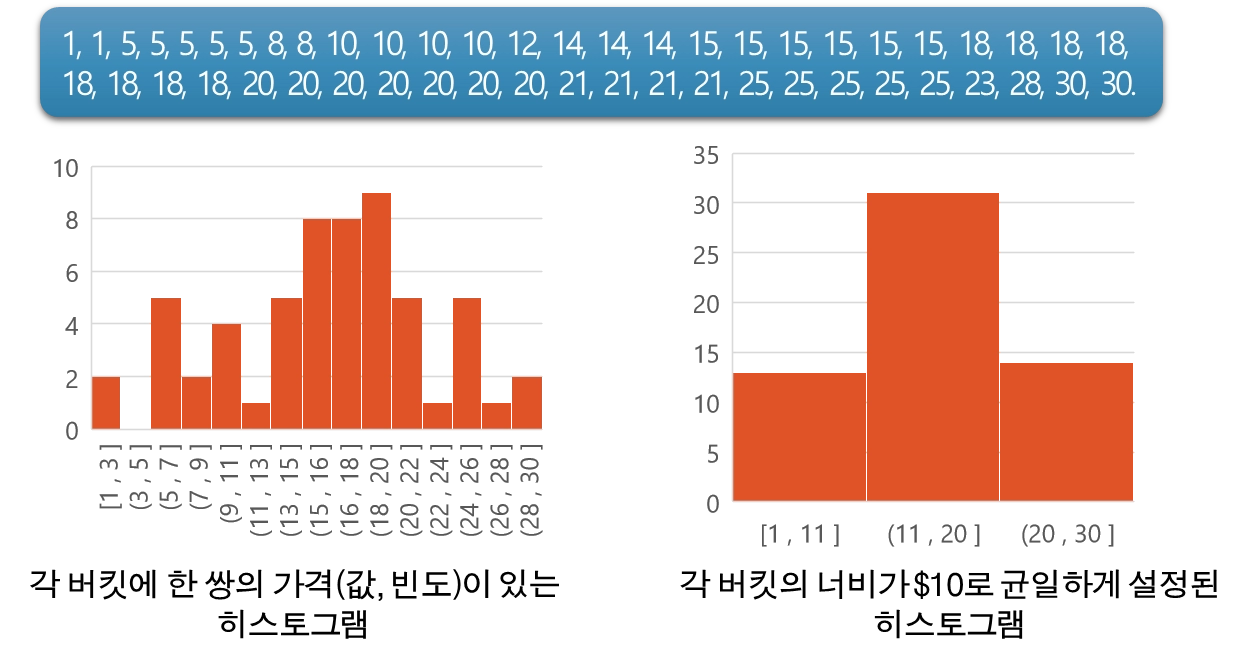
상점에서 판매되는 품목의 가격 목록(단위:$)
버킷을 활용한 인스턴스 축소 방법의 효과
•
연속형 변수도 범주형 변수로 구간을 분할해 이산화시킴
•
특정 분기점 이후로 데이터가 나뉘는 경우 유용함
•
회귀모델의 경우 예측력이 강화됨
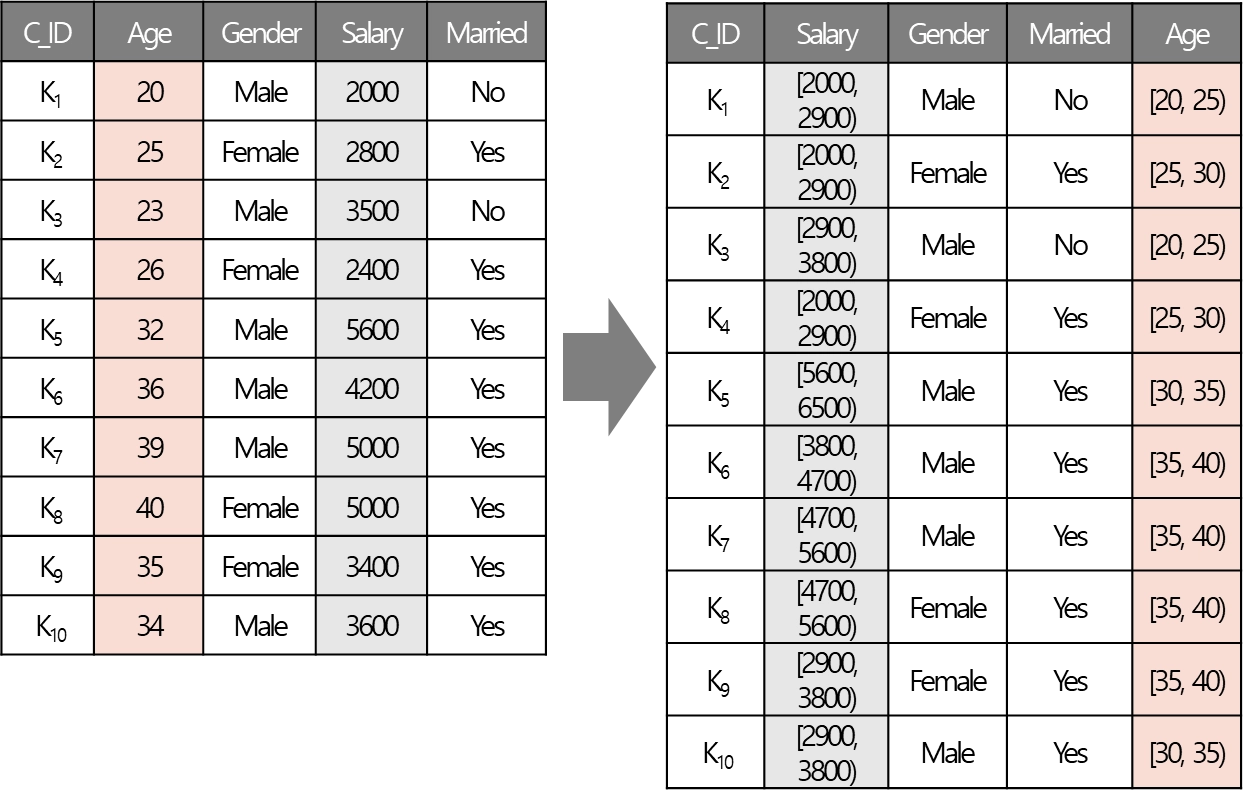
예시: 고객 데이터의 Salary와 Age에 개념 계층을 생성
pd.cut()
수치 데이터를 범주형으로 변환
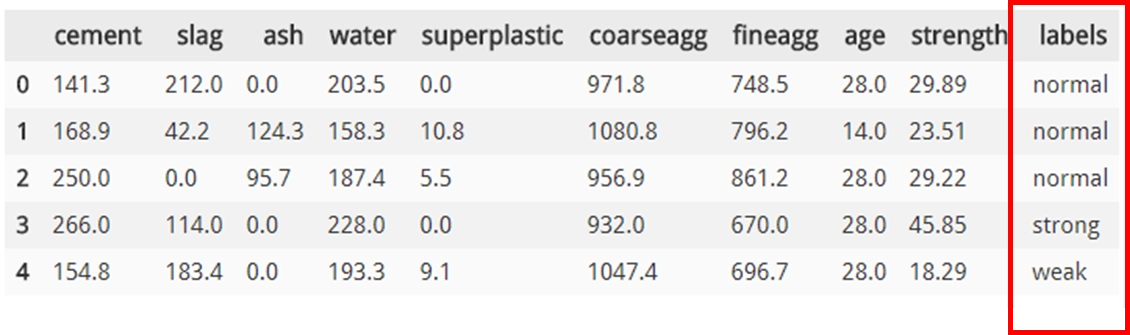
names = ['weak', 'normal', 'strong', 'strongest']
concrete['labels'] = pd.cut(concrete.strength, 4, labels=names)
concrete.head()
Python
복사
pd.qcut()
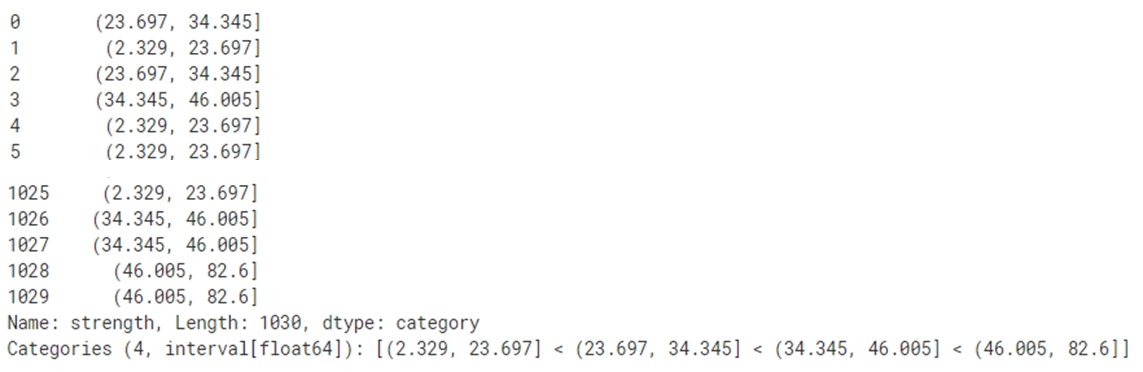
수치 데이터를 표본 변위치를 기준으로 버킷을 생성
pd.qcut(concrete.strength, 4)
Python
복사
concrete.groupby(pd.qcut(concrete.strength, 4)).size()
Python
복사

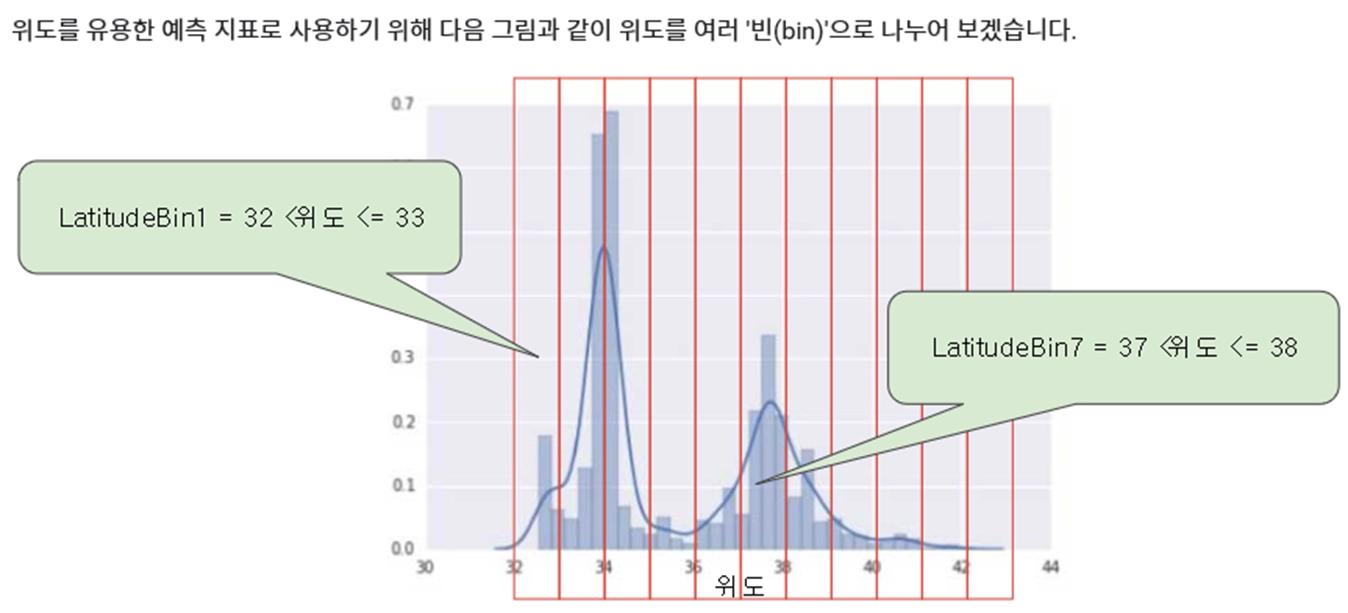
개념 계층 생성
•
연속 속성을 범주 속성으로 변환 (데이터 추상화)
•
원본 데이터를 단순화하고 마이닝 효율성을 높임
•
주어진 숫자 속성에 대한 개념 계층에 의해 정의
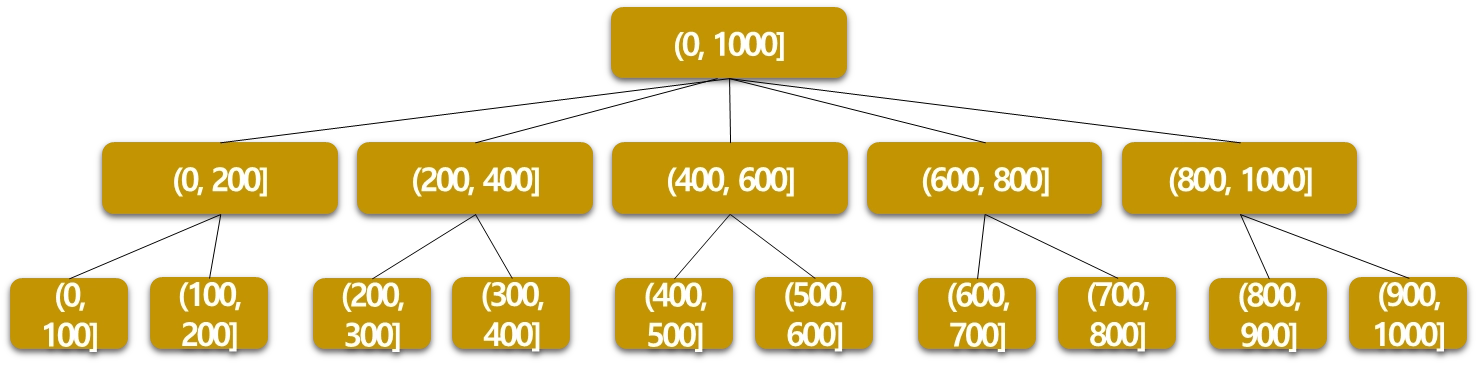
예시: 수치 데이터(가격)
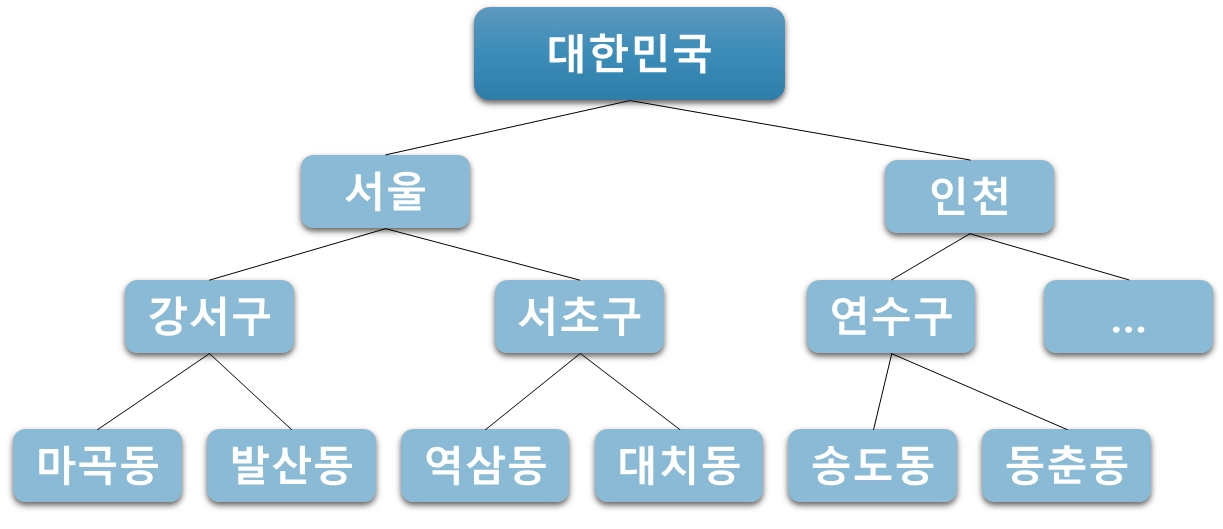
예시: 범주형 데이터(지역)
샘플링
•
데이터를 일부 추출하여 최적의 입력 데이터로 만들어 줌
•
머신러닝을 진행할 시에 입력 데이터가 많아지면 처리속도는 느려지기 때문에 대표되는 데이터를 샘플링 한 뒤, 머신러닝을 수행하면 학습 속도가 빨라짐
데이터 추출 방법 | 단순 랜덤 샘플링 | 단순 확률 추출, 무작위 추출 |
층화 샘플링 | 모집단을 동질적인 다수의 층으로 나누고, 층을 기준으로 단순 무작위 표본추출을 하는 방법 | |
데이터
재사용 여부 | 복원 추출법 | 추출한 데이터를 다시 모집단에 복원하여 추출하는 방법 |
비복원 추출법 | 추출한 데이터를 모집단에서 제외하는 방법 |
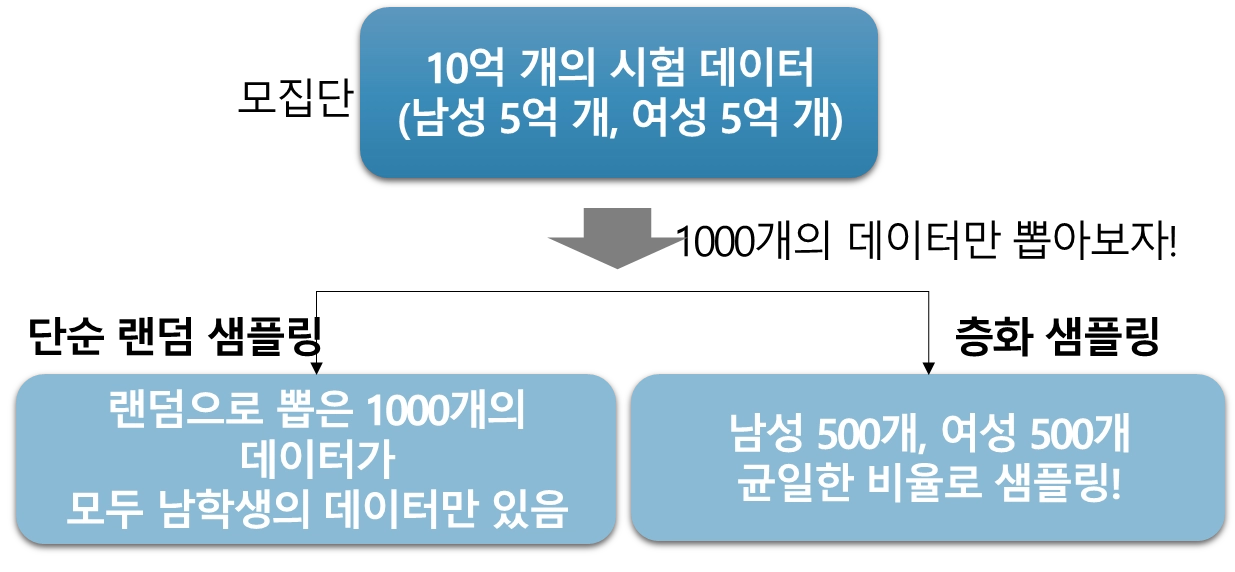
단순 랜덤 샘플링 vs 층화 샘플링
•
단순 랜덤 샘플링을 진행 했을 경우, 특정 집단의 데이터가 쏠려서 추출되는 경우가 발생할 수 있음
•
층화 샘플링은 모집단에서 집단 간의 비율을 고려하여 샘플링을 진행하기 때문에 이러한 문제 해결

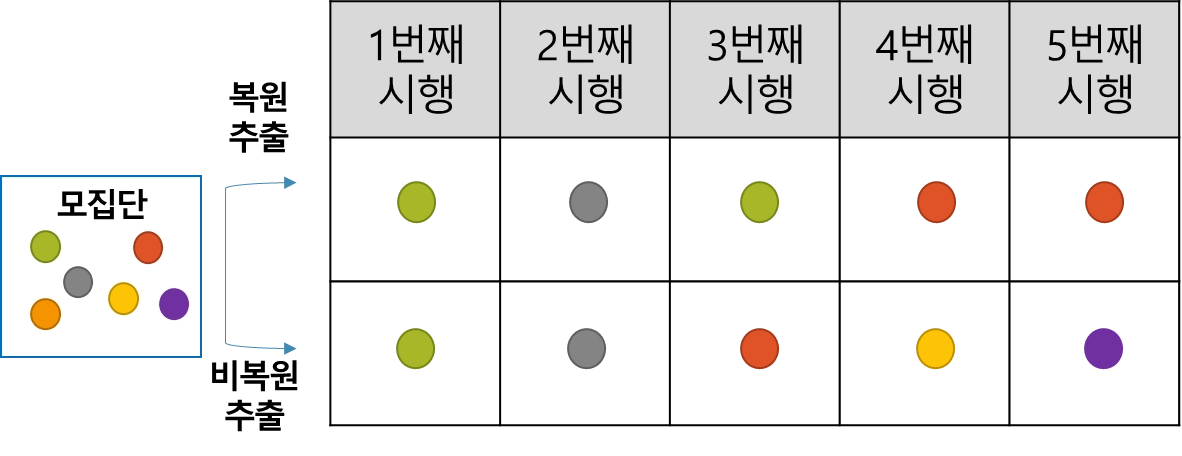
복원 추출 vs 비복원 추출
•
복원 추출에서는 한 번 사용된 데이터가 재사용 될 가능성이 있음
•
비복원 추출에서는 한 번 사용된 데이터는 다시 사용되지 않음