



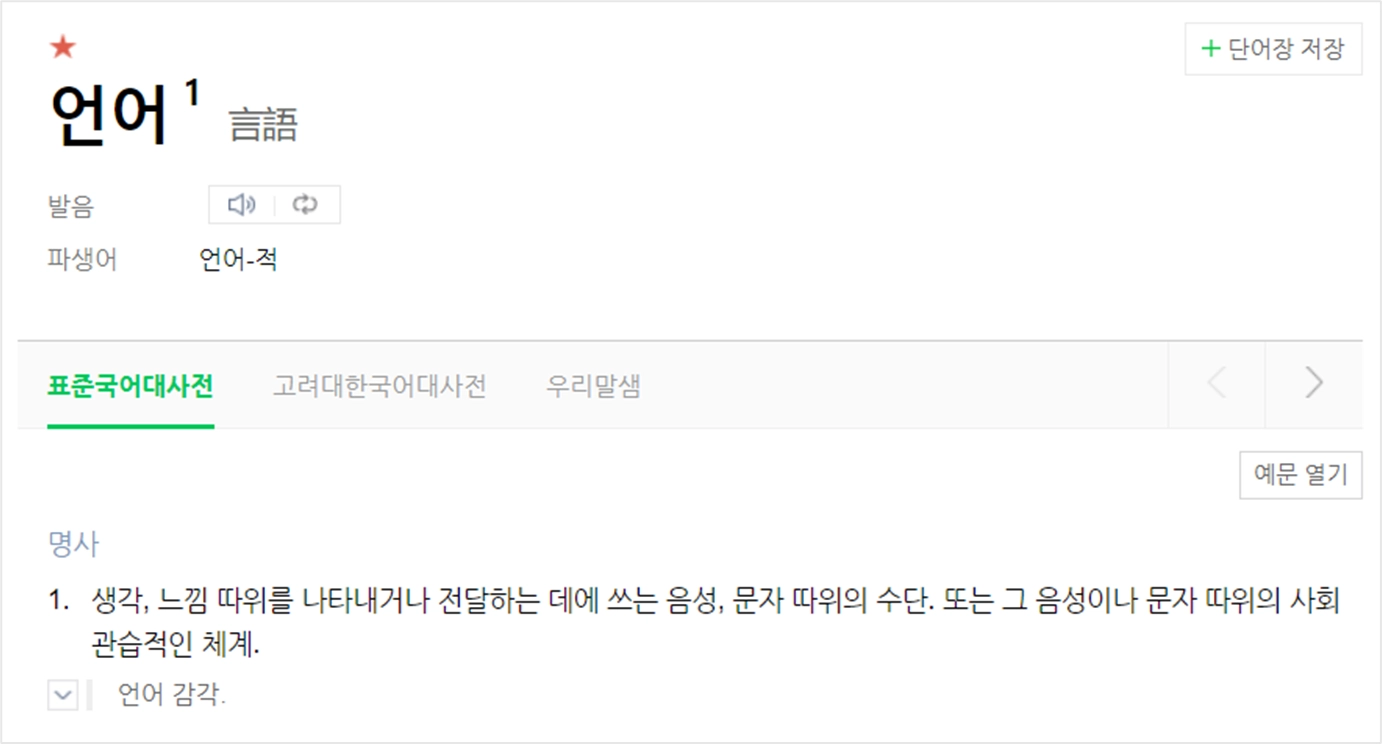
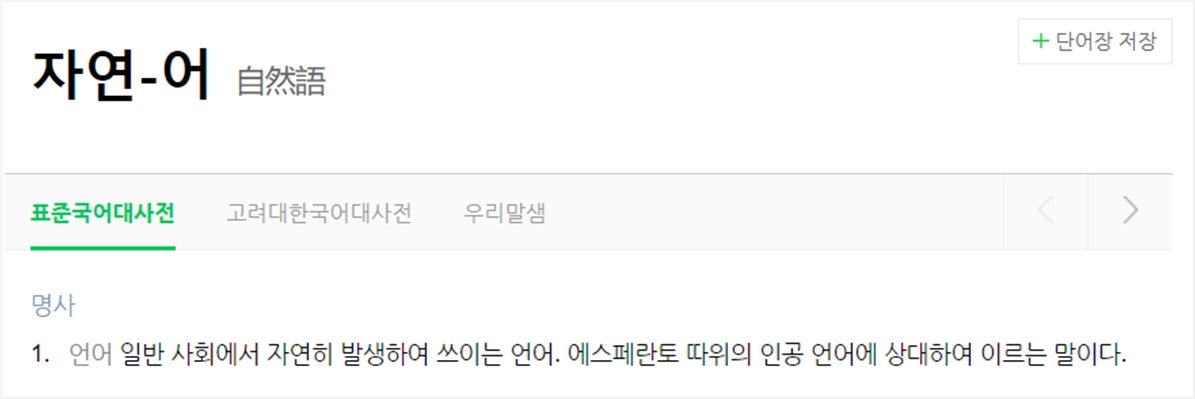
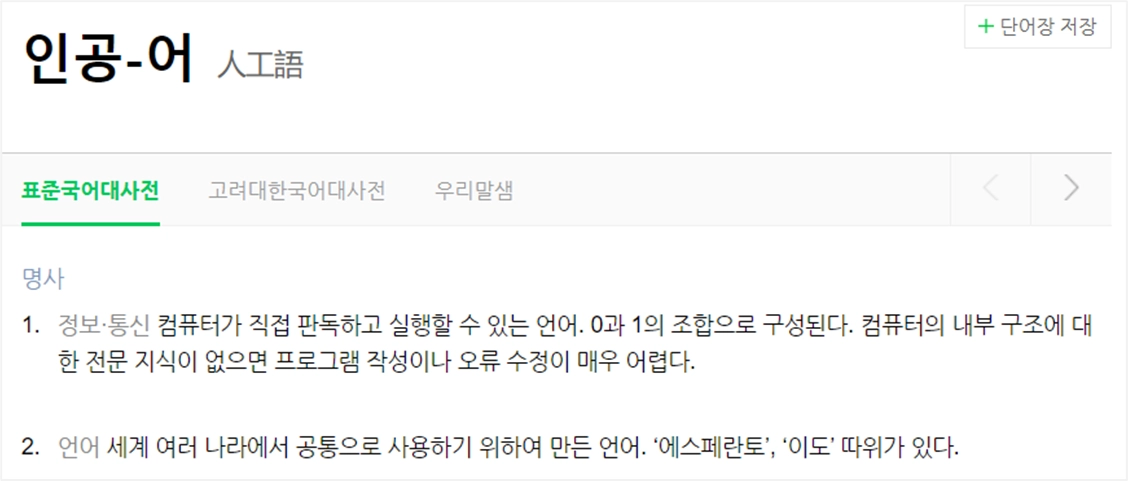
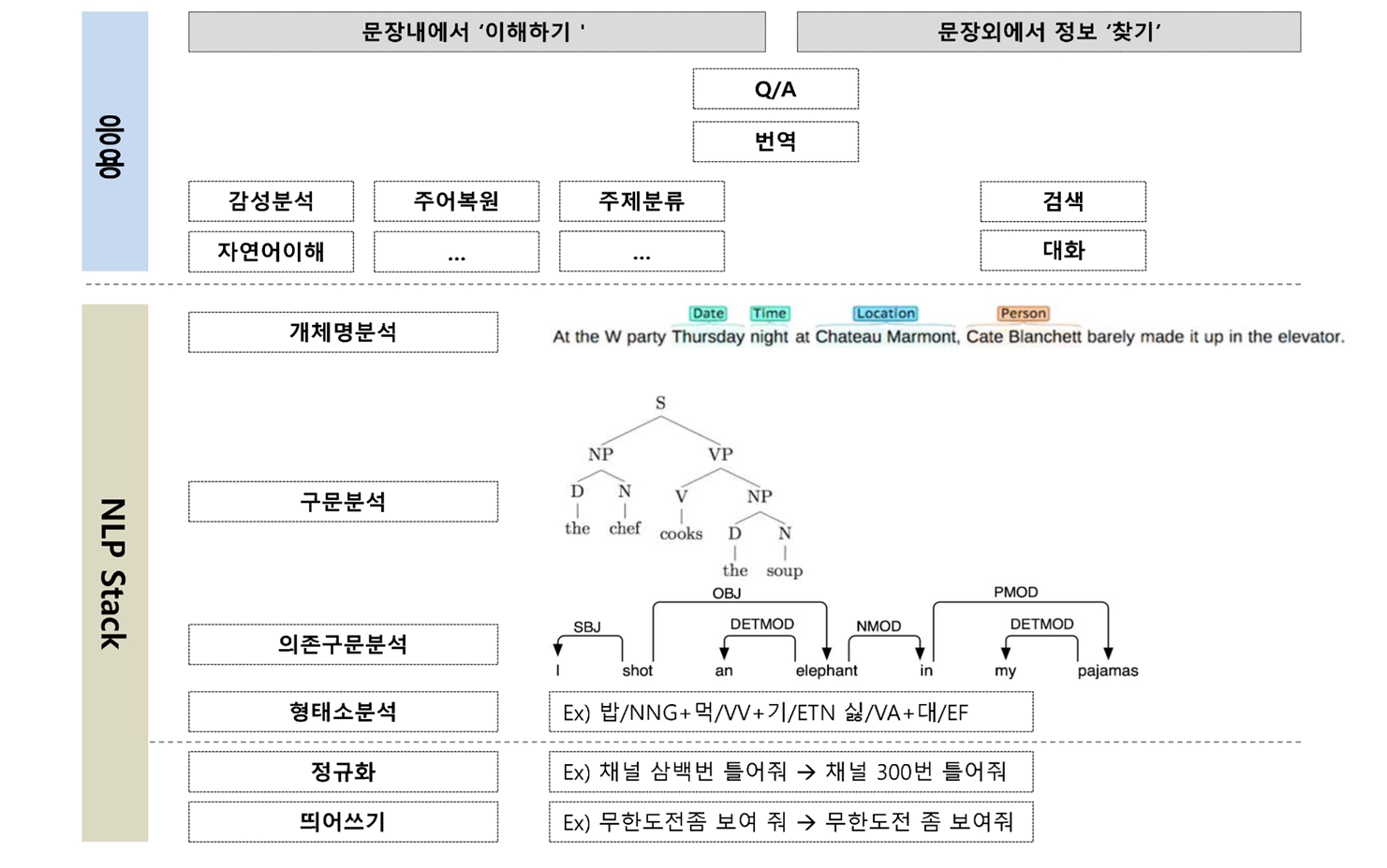
자연어란?
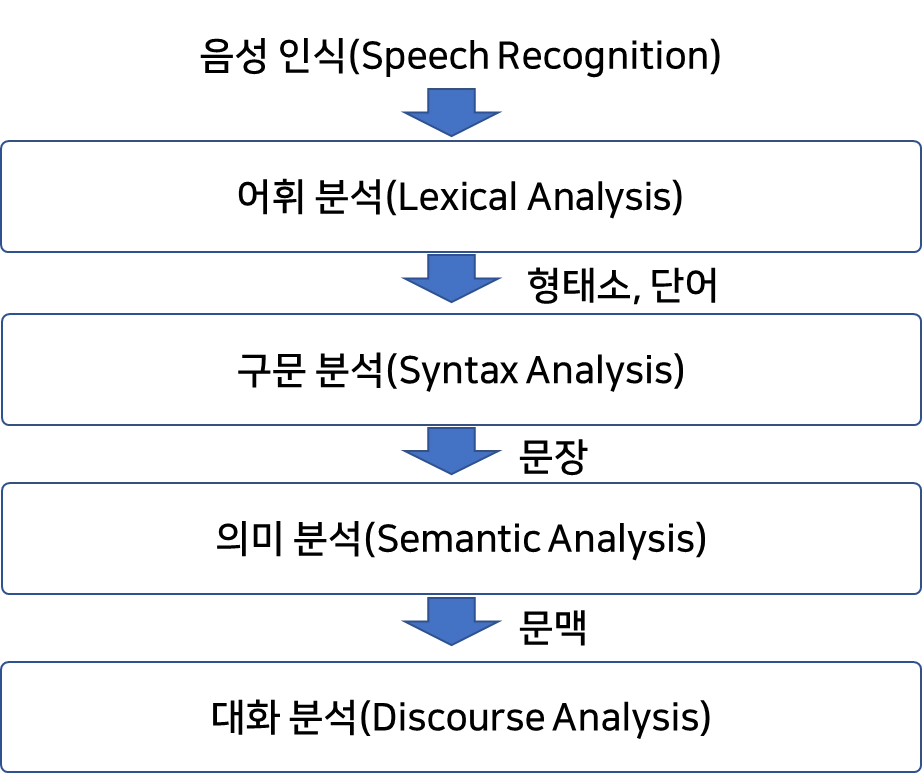
자연어 처리 단계
최근 20년간 자연어 처리 문제
텍스트 마이닝(Text Mining)

•
자연 언어 처리 기술을 활용하여 반정형/비정형 텍스트 데이터를 정형화하고, 특징을 추출하기 위한 기술
•
추출된 특징으로부터 의미 있는 정보를 발견할 수 있도록 하는 기술

•
텍스트 마이닝의 첫 시작은 ‘텍스트 정제’부터!
텍스트 정제 활동
CU에서 파는 찌이인~~~한 쪼꼬맛 아수쿠림인데 JMT
미안해애애애애애~~~ 사람이 느무느무 많았뜸.ㅠㅠㅠㅠㅠ 앞으로는 미리가서 사와야겠뜸 ٩('ù ’ ) و
오늘 아침 식단은 고구뇽스틱과 따아로 시작!!!!!!!!
식후땡 아슈크림 ۶(>___< ‘)
뭐행? 노라죠~
>▽<
>3<
ㅋㅋㅋㅋㅋㅋㅋㅋㅋ
\n\n\n\n\n\n\n\t\t\t
HTML
복사
•
개행문자 제거, 특수문자 제거, 공백 제거, 중복 표현 제거, 이메일/링크 제거, 제목 제거, 불용어 제거, 조사 제거, 띄어쓰기 , 문장분리 보정, 사전 구축
토큰화
자연어를 어떤 단위로 살펴볼 것인가
•
어절: 문장 성분의 최소 단위로서 띄어쓰기의 단위
•
형태소: 의미를 가지는 요소로서는 더 이상 분석할 수 없는 가장 작은 말의 단위
•
n-gram
•
His / mother / went / to / school / with / him
•
그/의/ 어머니/는/ 그/와/ 함께/ 학교/에 가/았/다
불용어 제거
기능어는 문장에서 실질적인 의미를 별로 가지고 있지 않기 때문에 불용어로 간주하여 제거
•
문장 = 지시어+ 기능어
◦
지시어:구체적인 대상이나 행동 상태를 가리킴
◦
기능어: 문법적인 기능
•
영어(관사, 전치사), 한국어(조사)
어근 동일화
•
어간 추출(stemming): 단어의 어미나 접두사, 접미사 등으로 해서 형태가 달라진 단어들을 형태소 분석을 통해 그 어간을 추출하여 동일한 단어로 간주하는 작업
•
표제어 추출(lemmatization):어간 추출의 단점 보완: 단어의 의미적 단위를 고려하지 않고 단어를 축약형으로 정리
어간 추출
(stemming) | 표제어 추출(lemmatization) | |
love, loves, loving, loved | lov | love |
innovation, innovations, innovate, innovates, innovative | innovat | •innovation(innovation, innovations)
•innovate(innovate, innovates)
•innovative(innovative) |
품사분석(Part of Speech tagging)
•
브라운 말뭉치(Brown corpus) 기반: 미국의 브라운 대학에서 구축, 87개의 표식 목록
◦
His(PPR$ 소유대명사) mother(NN 단수명사) went(VRD 동사과거형) to(TO, to) school(NN 단수명사) with(IN 전치사) him(PRP, 인칭대명사)
•
국립국어원의 세종 말뭉치 사전에 기반
◦
그(NP 대명사)의(JKG 관형격 조사)어머니(NNG 일반명사)는(JKS 주격조사)그(NP 대명사)와(JKB 부사격조사)함께(MAG 일반부사)학교(NNG 일반명사)에(JKB 부사격조사)가(VW동사)있(EC 연결어미)다(EF 종결어미)
말뭉치(corpus, 코퍼스)
자연어 처리로 정제하는 텍스트 데이터의 집합, 대용량의 정형화된 텍스트의 집합
•
코포라(corpora): 둘 이상의 코퍼스 모음
•
Google Books Ngram corpus, Brown corpus, American National corpus
•
코퍼스가 필요한 이유
◦
통계분석 수행: 빈도 분포, 단어의 동시 발생 등
◦
언어규칙 정의: 문법 교정 시스템
◦
문제 진술을 해결하기 위해 필요한 데이터 타입을 결정
텍스트 마이닝을 위한 파이썬 패키지
•
NLTK(Natural Language Toolkit): 자연어 처리 및 문서분석용 파이썬 패키지
https://www.nltk.org/index.html
•
KoNLPy: 한국어 자연어 처리
◦
5가지 형태소 분석기를 제공
◦
한나눔(Hannanum), 꼬꼬마(Kkma), 코모란(Komoran), 은전한잎(Mecan), OKT(이전의 Twitter)
•
Soynlp
핵심어 분석
•
핵심어(Keyword): 텍스트 자료의 중요한 내용을 압축적으로 제시하는 단어 또는 문구
•
핵심어 분석
◦
불용어 제거 등의 텍스트 전처리를 시행한 후, 텍스트에서 많이 등장하는 단어의 등장 빈도를 분석함으로써 핵심어를 추출하는 것
◦
텍스트의 주제가 무엇인지 짐작 가능
◦
텍스트가 서로 어느 정도 비슷한 지 파악
◦
인터넷 등에서 문서를 검색할 때 기초
◦
검색 엔진에서 검색결과의 우선 순위를 결정
•
핵심어 분석 방법
◦
단순 빈도를 제시하는 방법
◦
TF-IDF(Term Frequency-Inverse Document Frequency, 어휘 빈도-문서 역빈도)를 계산
◦
실습 코드: tf-idf
출현 빈도 카운트
•
◦
텍스트에 등장하는 단어를 그 등장 빈도에 따라 서로 크기가 다르게 구름형태로 표현
◦
어떤 단어가 많이 등장하고 어떤 단어가 적게 등장하는가를 한 눈에 알 수 있게 하는 방식
◦
단어들 사이의 연관성이나 의미 구조 등을 분석하는데 한계
◦
pip install wordcloud
◦

from wordcloud import WordCloud
# 단어 빈도수가 두 번 이상 나타난 단어에 대해서 wordcloud 생성
c = Counter(cleaned_noun_list)
len = 0
for key, val in c.items():
if(val > 1) :
len += 1
top_nouns = dict(c.most_common(len))
# print(top_nouns)
FONT_PATH = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
wordcloud = WordCloud(font_path=FONT_PATH, max_font_size = 60).generate_from_frequencies(top_nouns)
plt.figure()
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Python
복사
TF-IDF
•
Term Frequency-Inverse Document Frequency
•
어휘가 다른 문서에는 별로 등장하지 않고, 특정 문서에만 집중적으로 등장할 때 그 어휘야 말로 실질적으로 그 문서의 주제를 잘 담고 있는 핵심어라 할 수 있음
•
단어-문서 행렬TDM(Term-Document Matrix)
◦
빈도 분석 뿐 아니라 비슷한 단어들끼리 묶는 요인 분석이나 비슷한 문서끼리 묶는 군집분석, 단어들끼리의 동시 출현에 기반한 의미 연결망 분석, 토픽 모델링도 가능
의미 연결망 분석(Semantic Network Analysis)

•
단어 간의 관계를 분석하기 위해 사용
•
사회 연결망 분석 기법을 단어의 관계에 적용하여 텍스트의 의미 구조를 파악하려는 분석 기법
◦
(참고)사회 연결망 분석(SNA, Social Network Analysis)
▪
분석 대상(node)이 서로 어떻게 관련을 맺고 연결망(network)을 구성하는지 대상들 간의 관계를 연결망 구조로 표현하고 이를 계량적으로 제시하는 분석기법
▪
사회학, 경영, 인문, 공학 등 다양한 분야에서 활용
▪
예) SNS에서 서로 어떻게 연결되는가 분석
•
특정 단어가 어떤 단어와 함께 자주 사용되었는가?
•
문서의 저자가 강조하고자 하는 것이 무엇인지, 어떤 어조를 띄고 있는지 추측할 수 있음
SNA 분석 방법
•
문서를 구성하고 있는 단어를 노드로 구성하고 노드와 노드를 연결
•
네트워크 = 문서를 구성하고 있는 단어와 관계
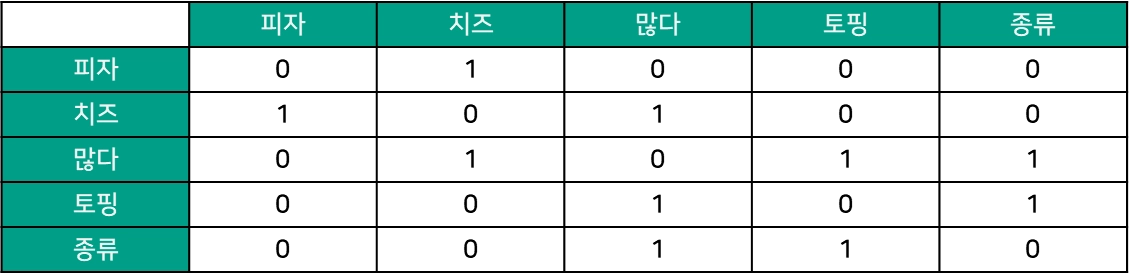
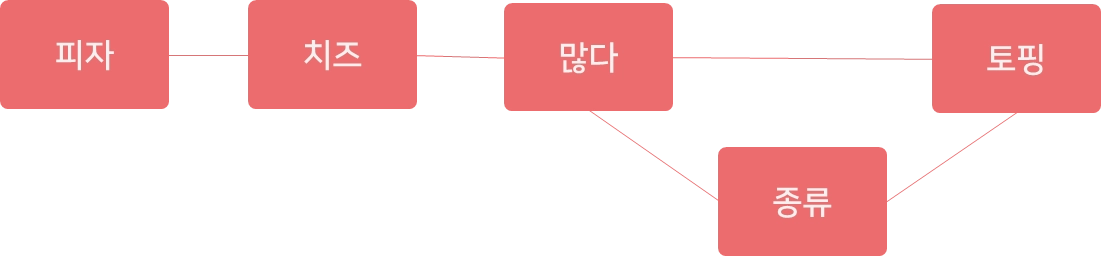
‘ㅇㅇ피자’ 시식평 SNA 분석
•
원문: 피자는 치즈!, 토핑 종류가 많아요, 치즈도 많네요
•
텍스트 정제: 피자, 치즈, 토핑, 종류, 많다,
•
인접행렬(Adjacent Matrix)
•
연결망 그래프
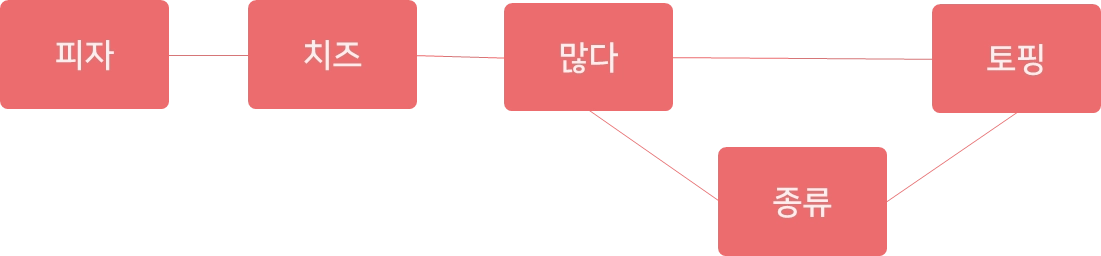
•
SNA 속성
◦
연결중심성
◦
매개중심성
◦
근접중심성

•
연결 중심성(Degree centrality)
◦
친구 수 (degree)가 많은 사람이 더 중심적 역할(한 단어에 직접 연결된 다른 단어의 수가 얼마나 많은지 측정)
◦
연결망의 크기에 따라 값을 비교하기 어렵기 때문에, 표준화 필요
◦
"특정 노드 i와 직접 연결된 노드 수" /"노드 i와 직간접적으로 연결된 모든 노드 수"
•
매개 중심성(Betweenness centrality)
◦
다리(bridge) 역할을 많이 하는 사람이 더 중심적 역할
◦
한 단어가 다른 단어들과의 연결망을 구축하는 데 매개자 역할을 얼마나 수행하는지 측정
◦
단어들의 등장 빈도가 낮더라도 매개 중심성이 높으면 단어들 간 의미 부여 역할이 커짐
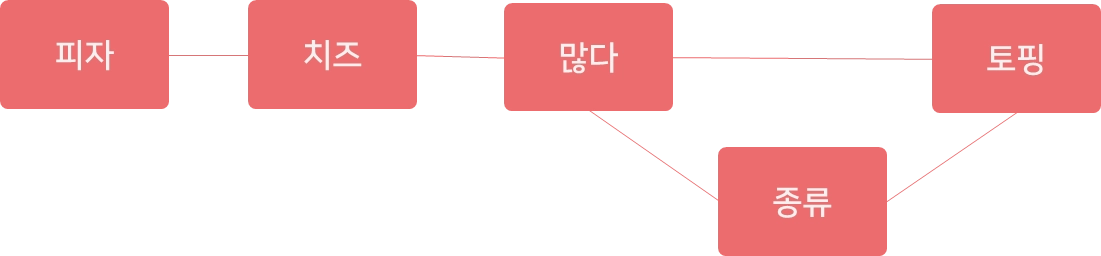

‘토핑’의 매개 중심성
•
근접 중심성(Closeness centrality)
◦
다른 노드와 더 가깝게 연결된 노드가 더 중심적 역할
◦
한 단어가 다른 단어에 얼마나 가깝게 있는지 측정
◦
직접 연결 뿐 아니라 간접적으로 연결된 모든 단어들 사이의 거리를 측정

‘피자’의 근접 중심성