


 목차
목차생성형 인공지능의 정의 및 연구 동향
초거대 AI
•
인공신경망, 딥러닝 기반으로 인간 수준의 매우 높은 성능을 보이는 범용적 AI 시스템
•
모델 파라미터(매개변수)가 무수히 많아, 대용량 데이터와 컴퓨팅 리소스를 사용하여 학습이 이루어짐
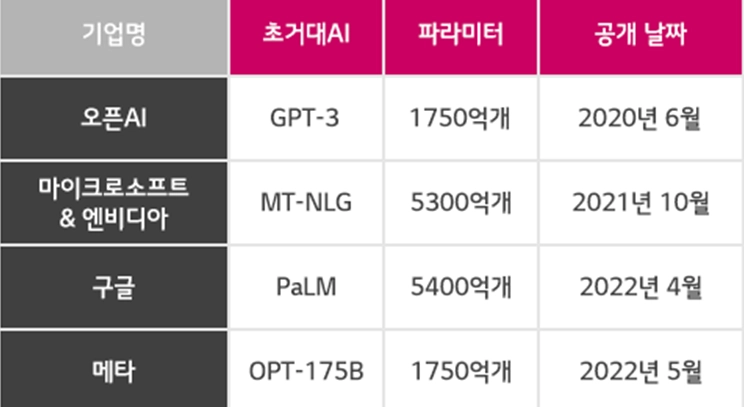
초거대 AI의 파라미터
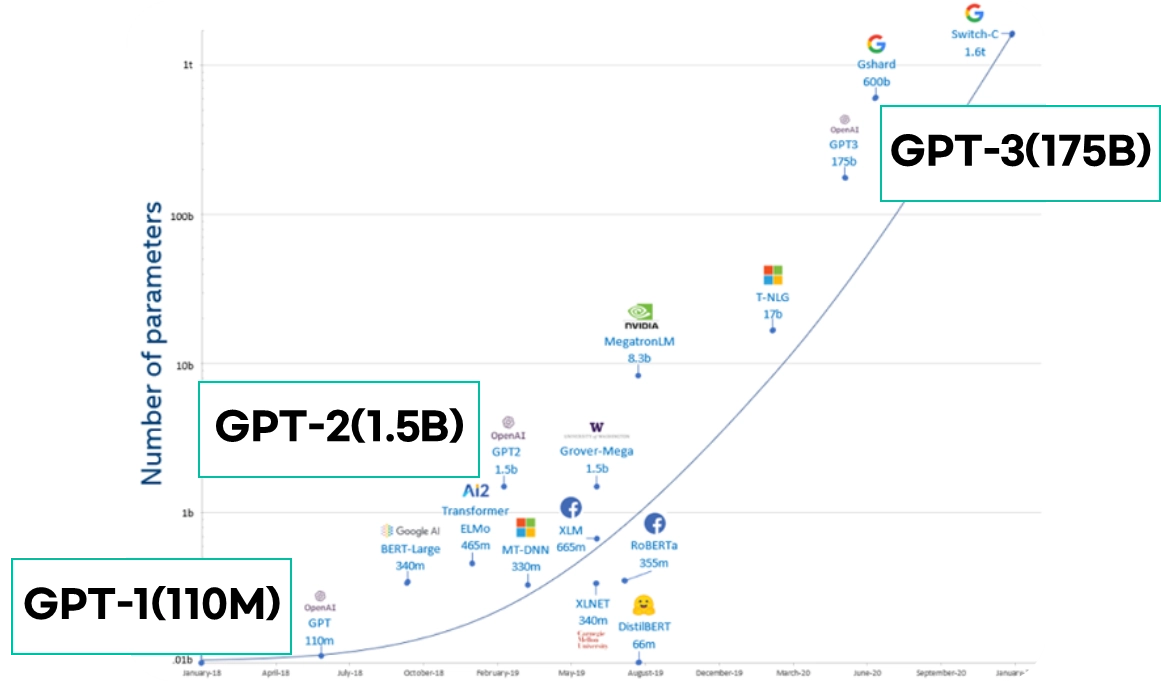
•
GPT3:1750억개의 파라미터
•
인간의 뇌: 약 1000억개의 뉴런
범용적 인공지능(AGI, Artificial General Intelligence)
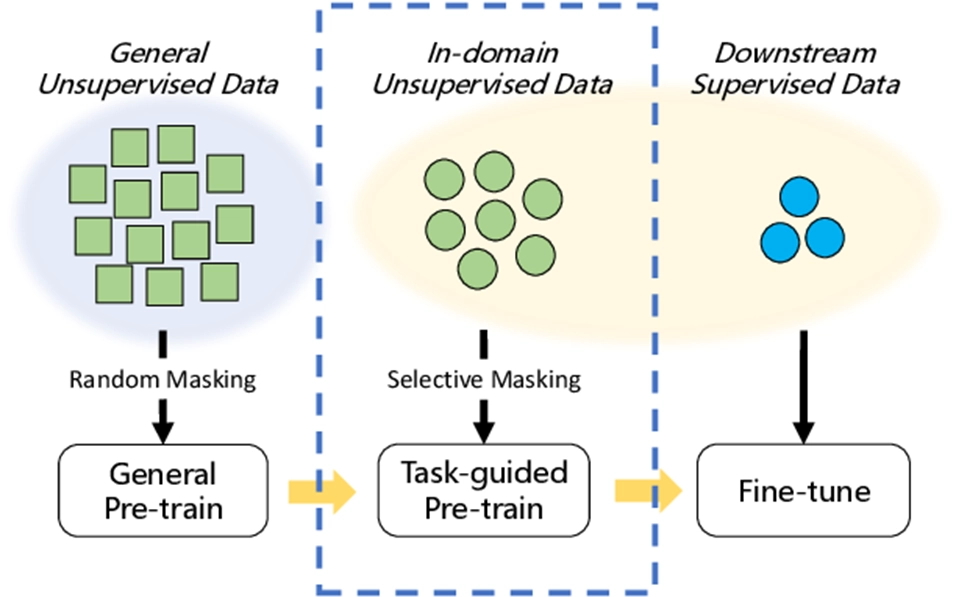
•
AGI 이전의 인공지능 학습은 크게 지도학습, 비지도 학습 방법으로 나뉘었음
•
AGI 인공지능 학습은 Pre training과정을 통해 지식을 습득한 이후 목적에 따라 Fine tuning하는 형태로 바뀜
주요 생성형 인공지능 모델의 사례 및 주요 특징
OpenAI
•
ChatGPT

•
OpenAI
◦
2015년 12월, 미국 캘리포니아에서 창립
◦
인간의 지능을 능가하는 AGI 개발을 지향
◦
2018년 GPT-1을 시작으로 DALL-E, GPT등 개발
◦
GPT3.5 모델 기반의 고성능 대화형 AI 서비스인 ChatGPT공개(’22.11)
ChatGPT 참고 영상
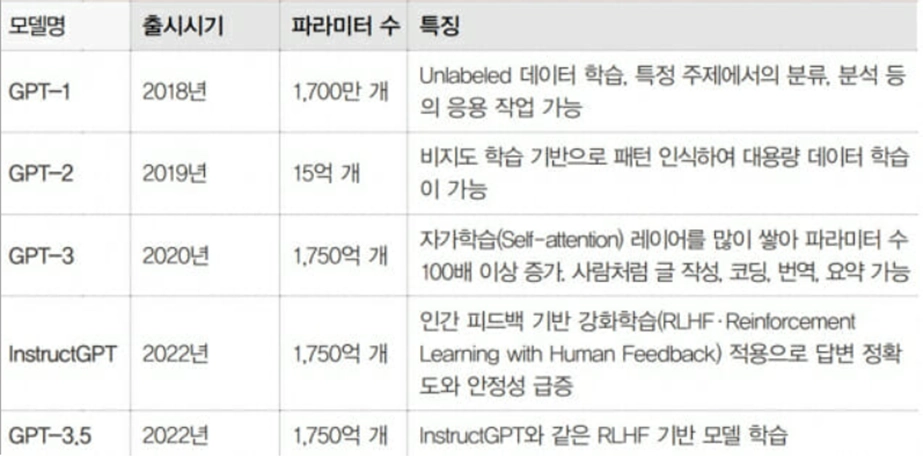
GPT 버전별 특징
삼일경영연구원

변호사 뒤통수 친 AI…챗GPT가 준 판례 믿었다가 ‘벌금’ [9시 뉴스] / KBS 2023.06.23.
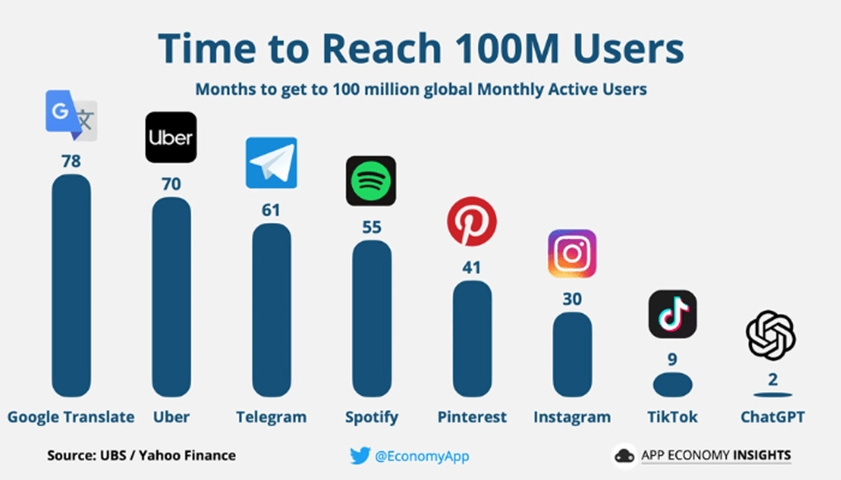
ChatGPT 서비스 주요 현황
•
2022년 12월 서비스 출시
•
5일만에 사용자 100만명, 첫달 사용자 5700만명, 최단기간 사용자 1억명 돌파
•
1월말 트래픽 7억건: 미국 21%
•
유료화: $20/M
•
작가 챗GPT

Microsoft
•
Microsoft의 투자
◦
2016년 OpenAI와 협약
◦
2019년 OpenAI와 독점적 파트너쉽(10억 달러)
◦
2023년 1월, 100억 달러 추가 투자 계획
◦
OpenAI기술을 기반으로 AI 플랫폼 사업화 계획
•
Microsoft 서비스 + AI 플랫폼
◦
Bing
▪
DALL-E(이미지 생성), ChatGPT(자연어 질문/답변)
◦
Office
▪
ChatGPT(보고서 요약, 제안서 작성, 문장 자동 완성)
▪
DALL-E(프리젠테이션 이미지)
◦
Outlook
▪
ChatGPT(메일작성)
◦
Azure OpenAI
▪
Codex(자연어로 코딩)
▪
DALL-E(웹페이지용 이미지 생성)
▪
ChatGPT(고객 응대, 검색)
•
MS Copilot
Bard
•
’23년 2월, LaMDA 언어 모델 기반 Bard 발표
◦
’17년 트랜스포머 발표 이후, BERT, LaMDA등 비지도 사전학습 모델들을 지속적으로 발표

•
LaMDA(Language Model for Dialogue Application)
◦
대화 시스템을 위한 언어모델(Google I/O 2021)
◦
다양한 주제에 대해서도 맥락을 잘 이해하여, 자연스럽고 연속적인 대화 가능
◦
트랜스포머 기반 언어모델
◦
BERT와 달리 대화 텍스트를 학습하여 뉘앙스 등 파악 가능
•
LaMDA vs ChatGPT
◦
How popular LLMs score along human cognitive skills
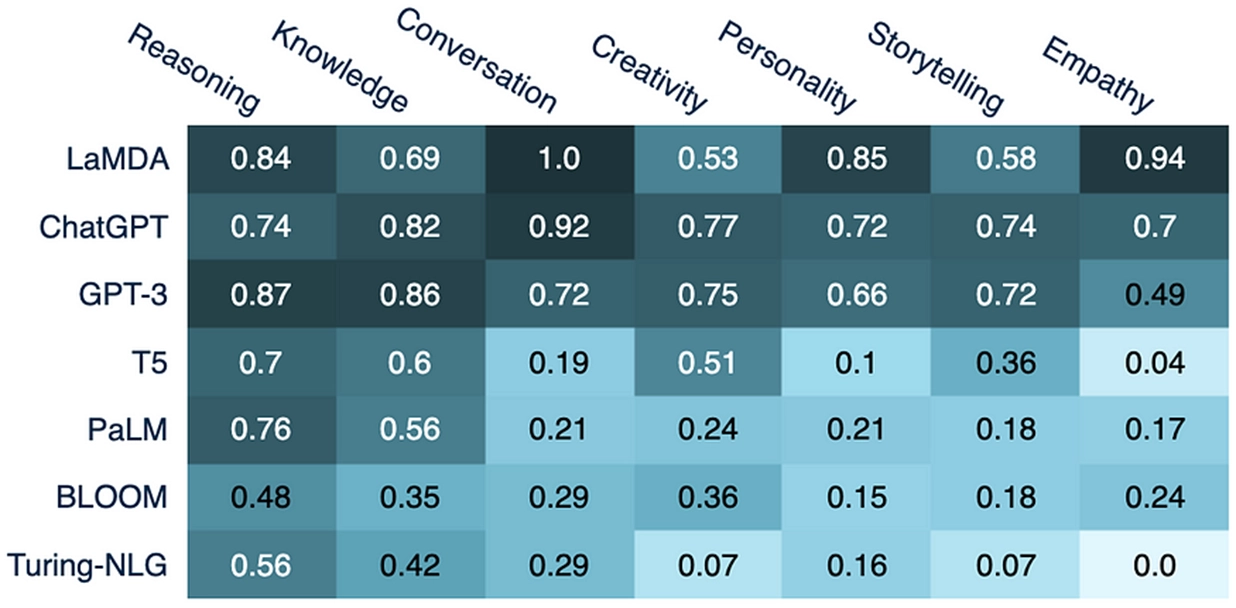
(source: semantic embedding analysis of ca. 400k AI-related online texts since 2021)
이미지 생성 모델(Text-to-image generation)
•
실사같은, 예술적 스타일 이미지에서 기존에 존재하지 않는 이미지까지 생성
•
상상의 세계를 시각적으로 표현
•
고품질 이미지 생성
•
개념의 창의적 결합
Text-to-image 기술의 발전

•
GAN(2014) → DALL-E(2021.1) → Stable Diffusion(2021.12) → Midjourney(2022.8) → Visual ChatGPT(2023.3)
•
주요 대기업은 기술 연구는 지속하고 있으나, 대중 서비스에 대해 보수적
•
유해성, 편향성 등 이슈로 논문은 공개하나 코드, 학습데이터, 모델은 비공개 경향
•
OpenAI, Stability AI, Midjourney등 신생 기업 주도 서비스(2022~)
•
StabilityAI 코드 공개 이후 AI 이미지 생성 유사 서비스 증가
DALL-E(OpenAI)
•
WALL-E 로봇(Pixar) + 초현실주의 예술가 살바도르 달리(Salvador Dali)
◦
달리처럼 창의적, 초현실주의적으로 그려주는 로봇(?)
•
대중적으로 활용 가능한 최초의 AI 기반 text-to-image 서비스
◦
예술과 상상의 창의적 콘텐츠를 생성할 수 있는 새로운 도구로 진입
•
DALL-E(’21년 1월), DALL-E 2(’22년 9월)
•
Cosmopolitan 잡지 커버(’22년 6월)

•
DALL-E 2 의 한계
◦
글자 생성, 복잡한 장면(예. 손가락, 눈 표현 등)에서 어색함
◦
A sign that says deep learning

◦
물체의 속성 결합 제한
◦
“a red cube on top of a blue cube”

Image Creator(Microsoft)
•
검색엔진 Bing에 연동한 Text to image 서비스
•
무료, 한글 입력 가능(영어 추천)
•
해상도: 1024x1024
Imagen(Google)
•
Diffusion Model 기반 text to image
•
코드, 데이터 셋, 학습 모델은 윤리적 이슈, 사회적 편향성, 유해성 이슈로 비공개
•
Imagen vs DALL-E2의 비교

MidJourney
•
텍스트나 이미지를 AI를 통해 그림으로 생성해주는 서비스(’22년 7월 출시)
•
디스코드 서버에서 봇을 이용하는 형태로 사용
•
웹툰에서 실사까지 다양한 장르와 다양한 퀄리티의 결과물이 창작 가능
생성형 AI의 이슈
독일의 한 사진작가가 인공지능(AI)으로 만든 이미지를 국제 사진전에 출품한 뒤 우승작으로 선정되자 뒤늦게 AI 작품임을 밝혀 논란이 되고 있다. 작가는 이후 수상을 거부했다.
18일(현지시간) 영국 BBC에 따르면 독일 출신 사진작가 보리스 엘다크젠은 세계 최대 사진 대회 중 하나인 '2023 소니 월드 포토그래피 어워드'(SWPA) 크리에이티브 오픈 카테고리 부문에서 1위를 차지했다.
엘다크젠은 이 대회에 젊은 여성과 노년의 여성의 모습이 담긴 흑백 이미지를 출품했다. '전기공'(The Electrician)이라는 제목의 사진 속 노년의 여성은 젊은 여성 뒤에서 그의 어깨를 붙잡고 어딘가를 응시하고 있다.
작가는 해당 작품이 수상작으로 뽑히자 그제야 AI로 만든 사진임을 밝히면서 상을 받지 않겠다고 말했다.

지난달 26일(현지시간) 미국 ‘콜로라도 주립 박람회 미술대회’의 디지털아트 부문에서 우승을 차지한 제이슨 M. 앨런(39)은 최근 뉴욕타임스(NYT)와의 인터뷰에서 이렇게 소감을 밝혔다. 그가 미술대회에 출품한 작품이 AI프로그램으로 제작한 것이기 때문이다.
AI로 만든 작품의 미술대회 우상 소식은 사회관계망서비스(SNS)에서 퍼지며 논란을 키웠다. 게임기획자인 앨런은 미술대회 수상 소식을 SNS인 디스코드에 올렸고, 이 소식이 트위터로 옮겨지며 예술가들은 물론 누리꾼 사이에서도 갑론을박이 펼쳐졌다. AI 작품은 표절에 지나지 않는 것인지, 아니면 AI 프로그램이 예술가의 또다른 도구가 될 수 있을지에 대해서 의견이 엇갈리고 있다.
