•
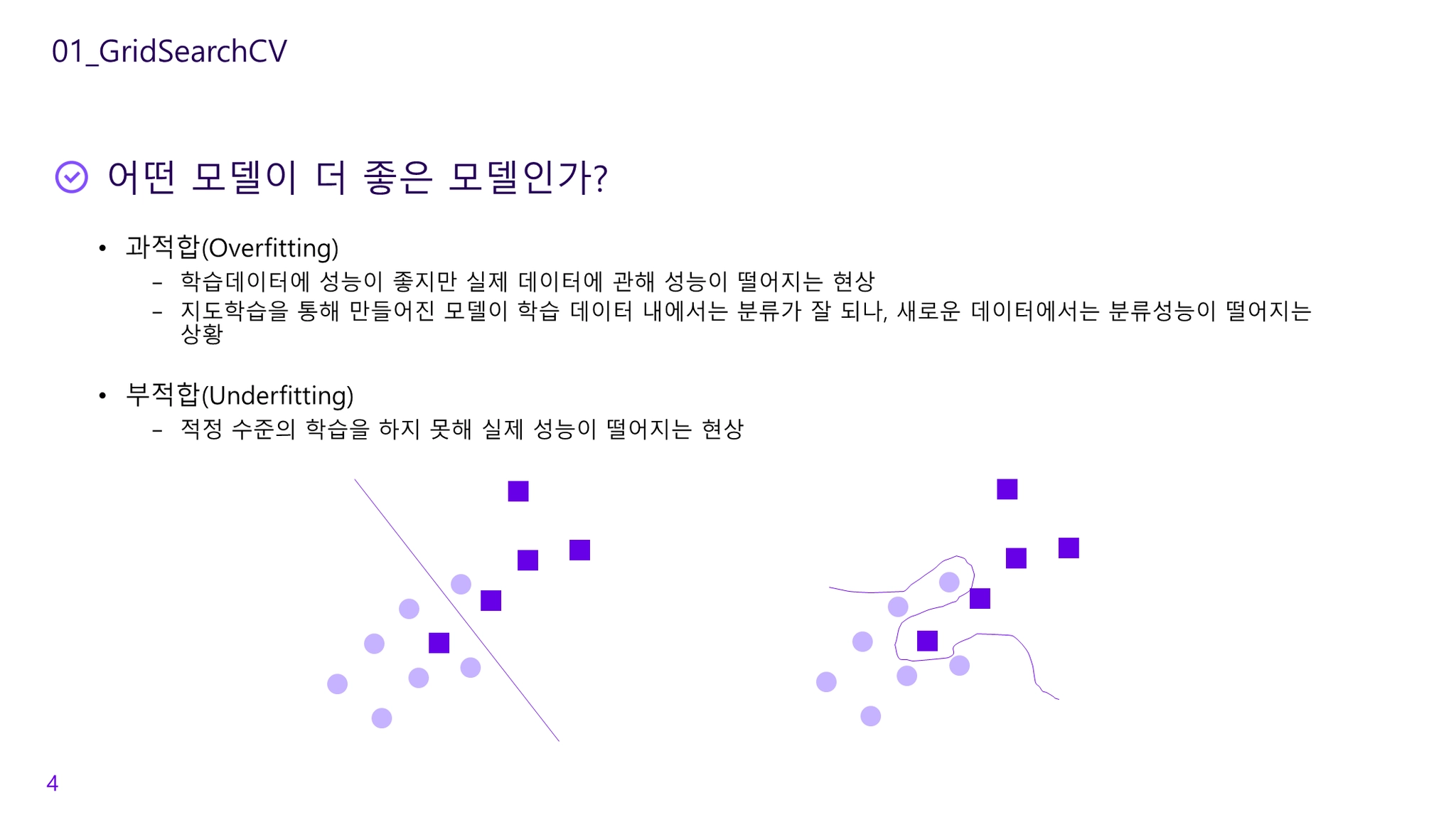
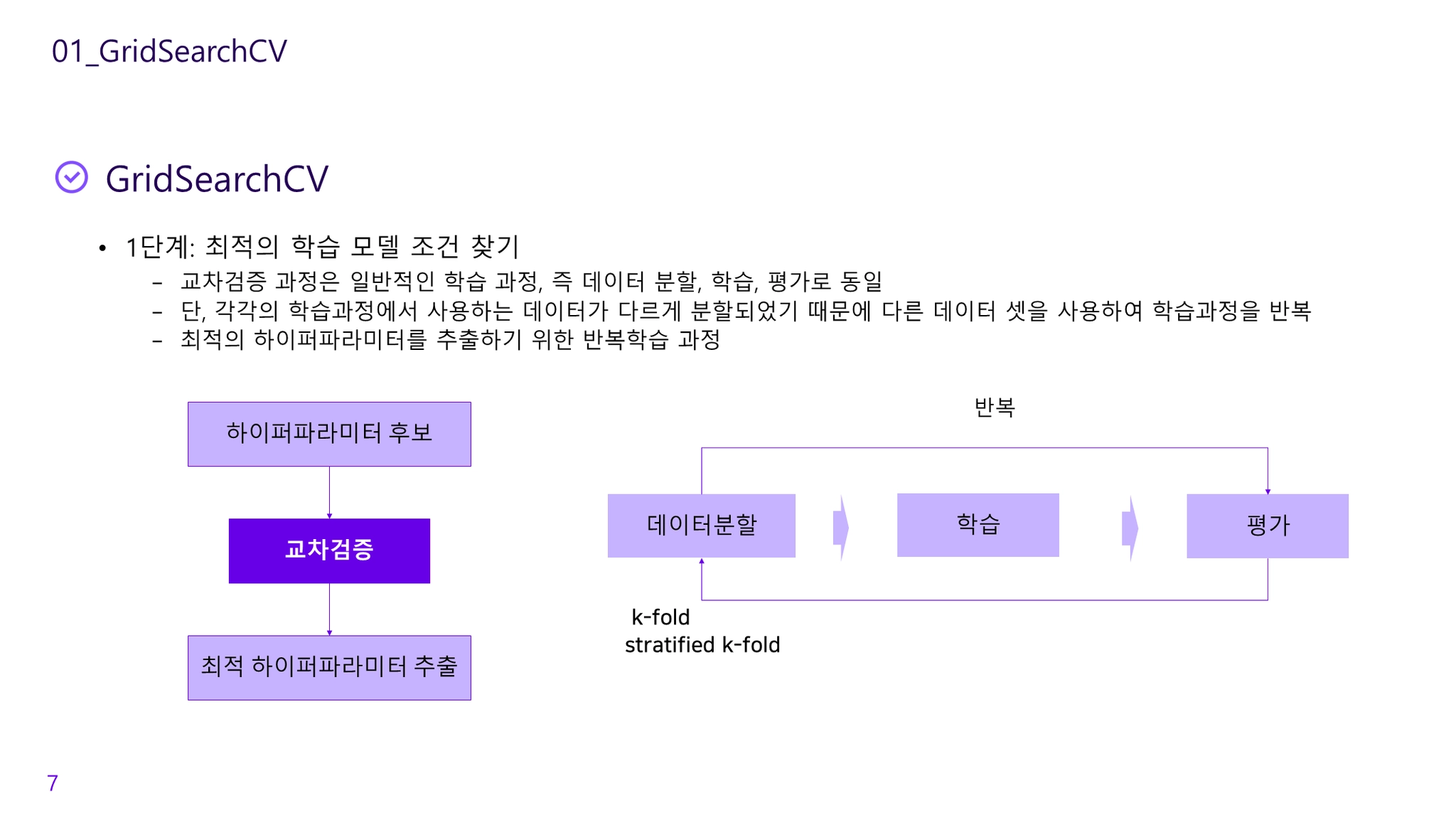
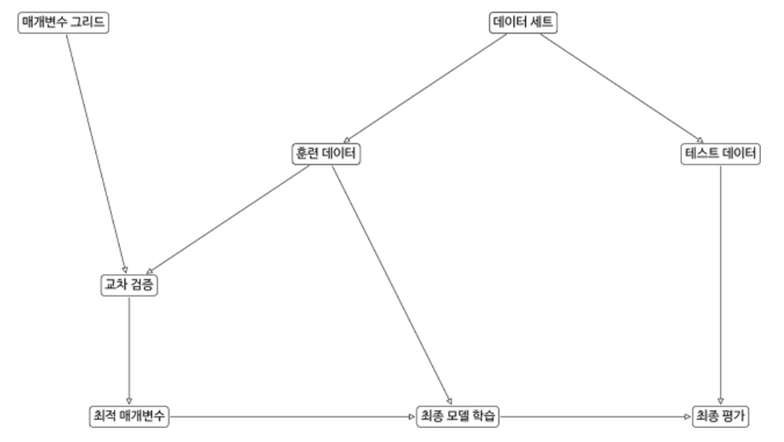
관심있는 매개변수들을 대상으로 가능한 모든 조합을 시도하여 매개변수들을 튜닝하여 일반화 성능을 높이는 방법
•
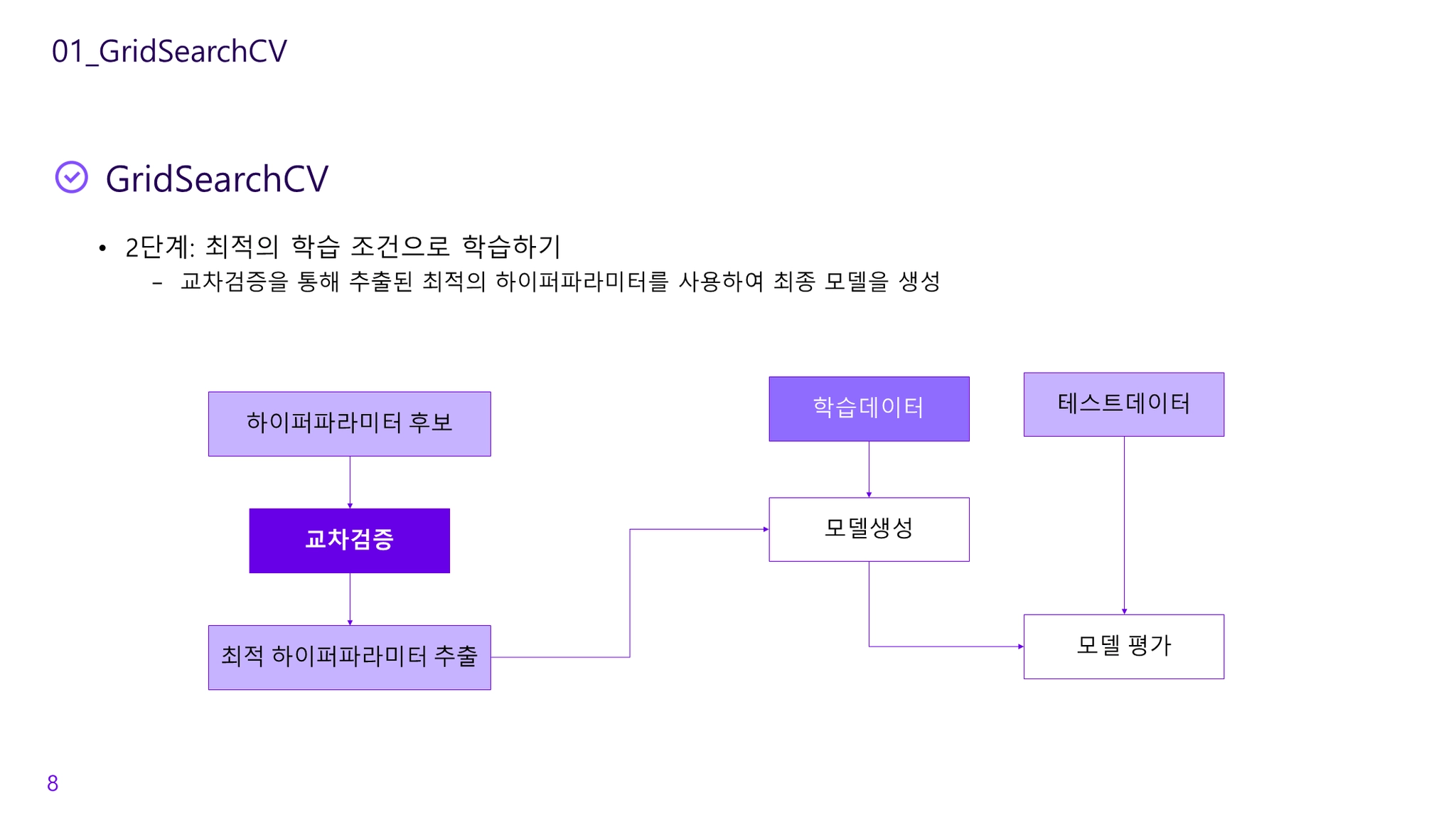
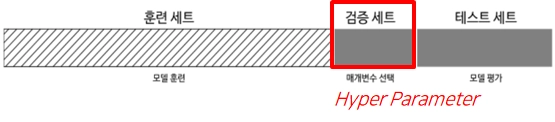
검증세트를 사용해 최적의 매개변수를 선택한 후, 그 매개변수에서 훈련 세트와 검증 세트 데이터를 이용해 모델을 다시 만듦
◦
[주의] 테스트세트를 사용하여 매개변수 범위 테스트를 해서는 안됨. 테스트세트를 사용한 평가는 모델이 결정되고 마지막에 딱 한 번 수행해야함
•
교차검증을 기반으로 하이퍼파라미터의 최적값을 찾아줌
•
수행시간이 상대적으로 오래걸림
주요 Parameter

Sample Code
from sklearn.model_selection import GridSearchCV
import pandas as pd
model = DecisionTreeClassifier()
# parameter를 dictionary 형태로 설정
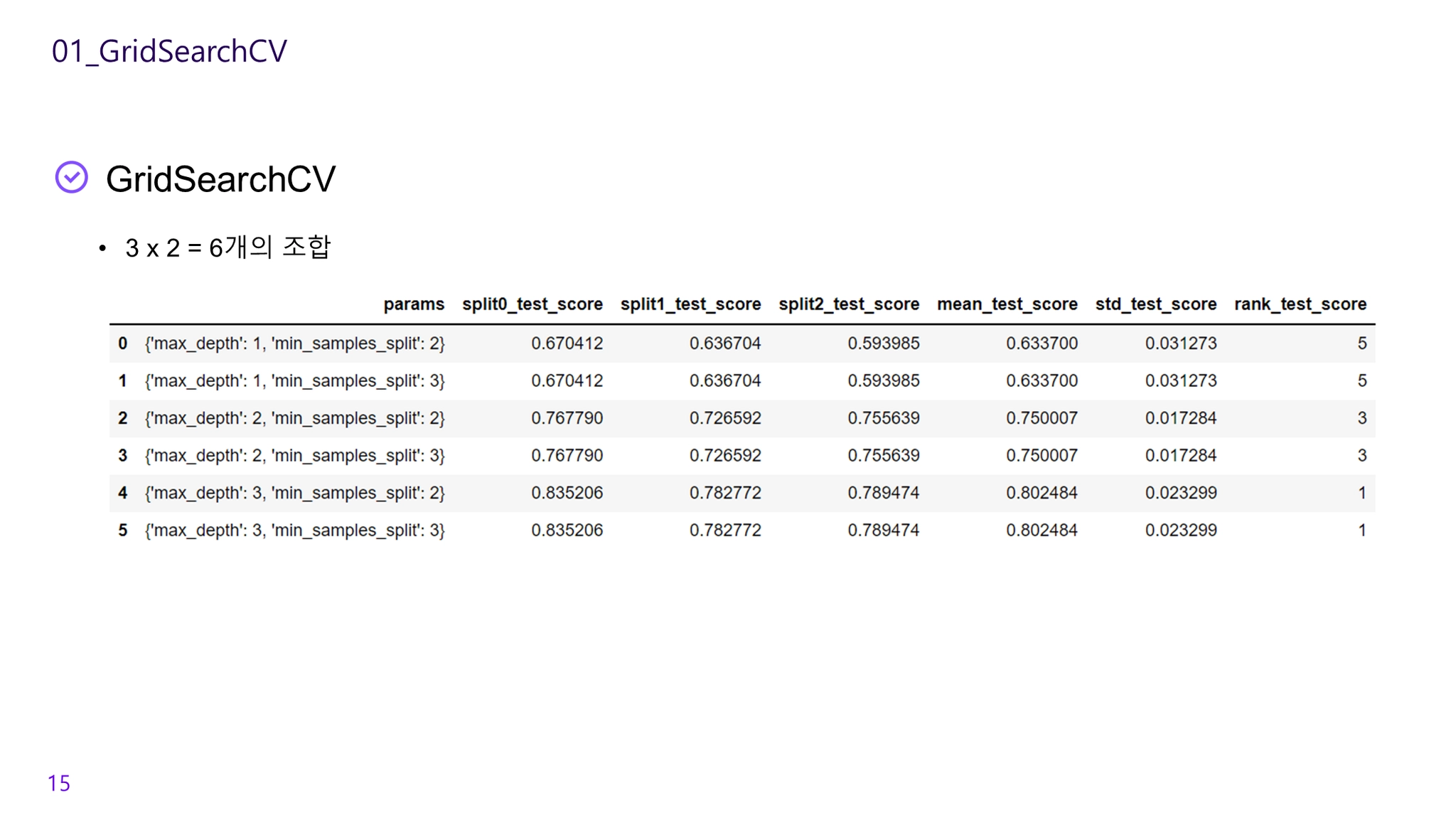
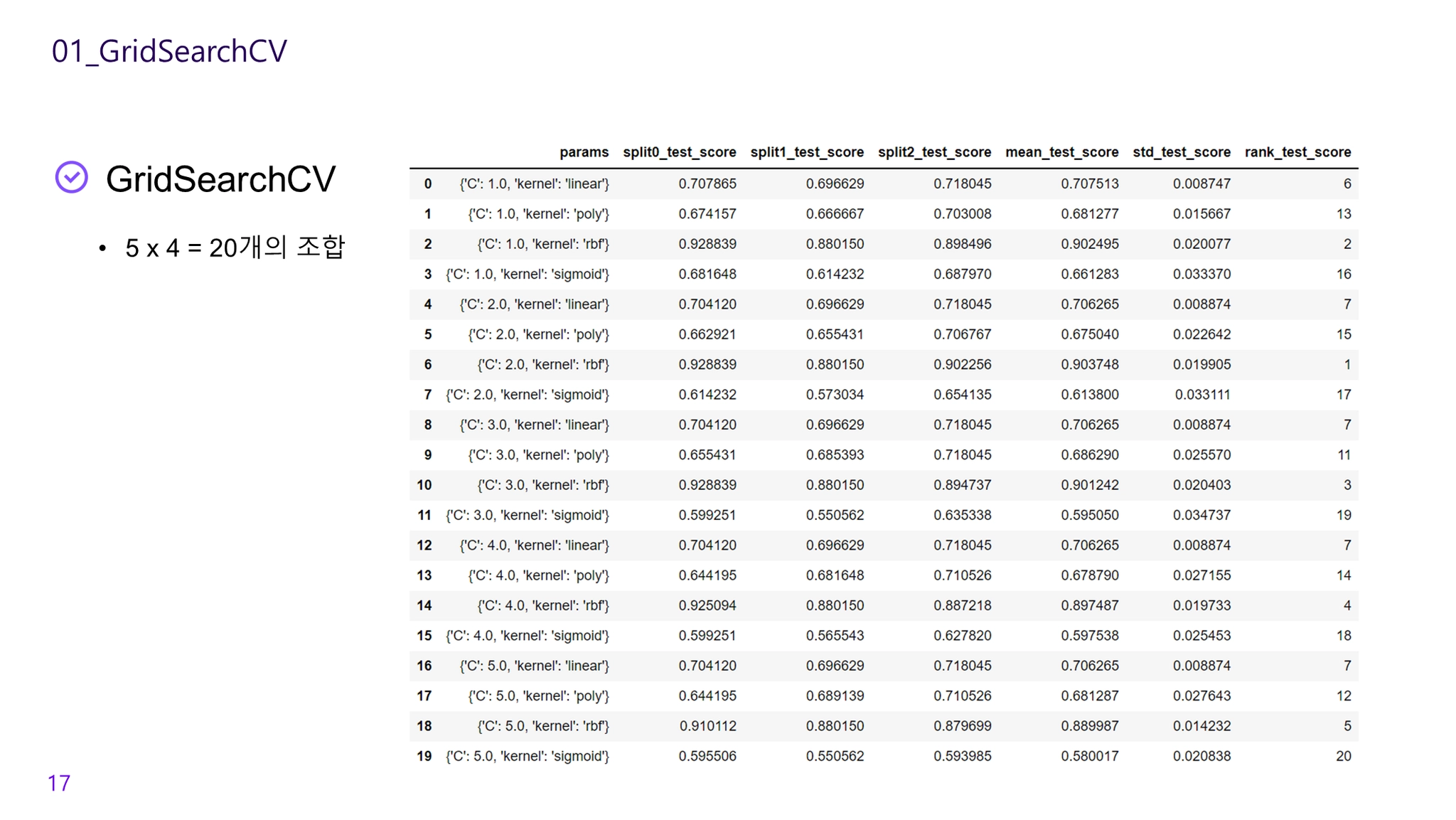
parameters = {'max_depth':[1,2,3], 'min_samples_split':[2,3]}
# 의사결정나무 모델을 데이터 셋을 3등분하여 학습
# 가장 좋은 파라미터 설정으로 재 학습(refit=True)
grid_model = GridSearchCV(model, param_grid=parameters, cv=3, refit=True)
grid_model.fit(X_train, y_train)
# GridSearchCV 결과 추출하여 DataFrame으로 변환
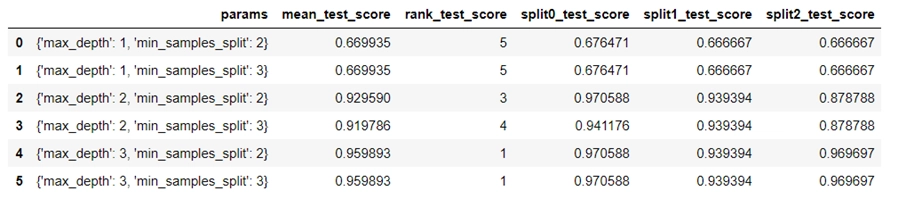
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score',
'split0_test_score', 'split1_test_score', 'split2_test_score']]
Python
복사
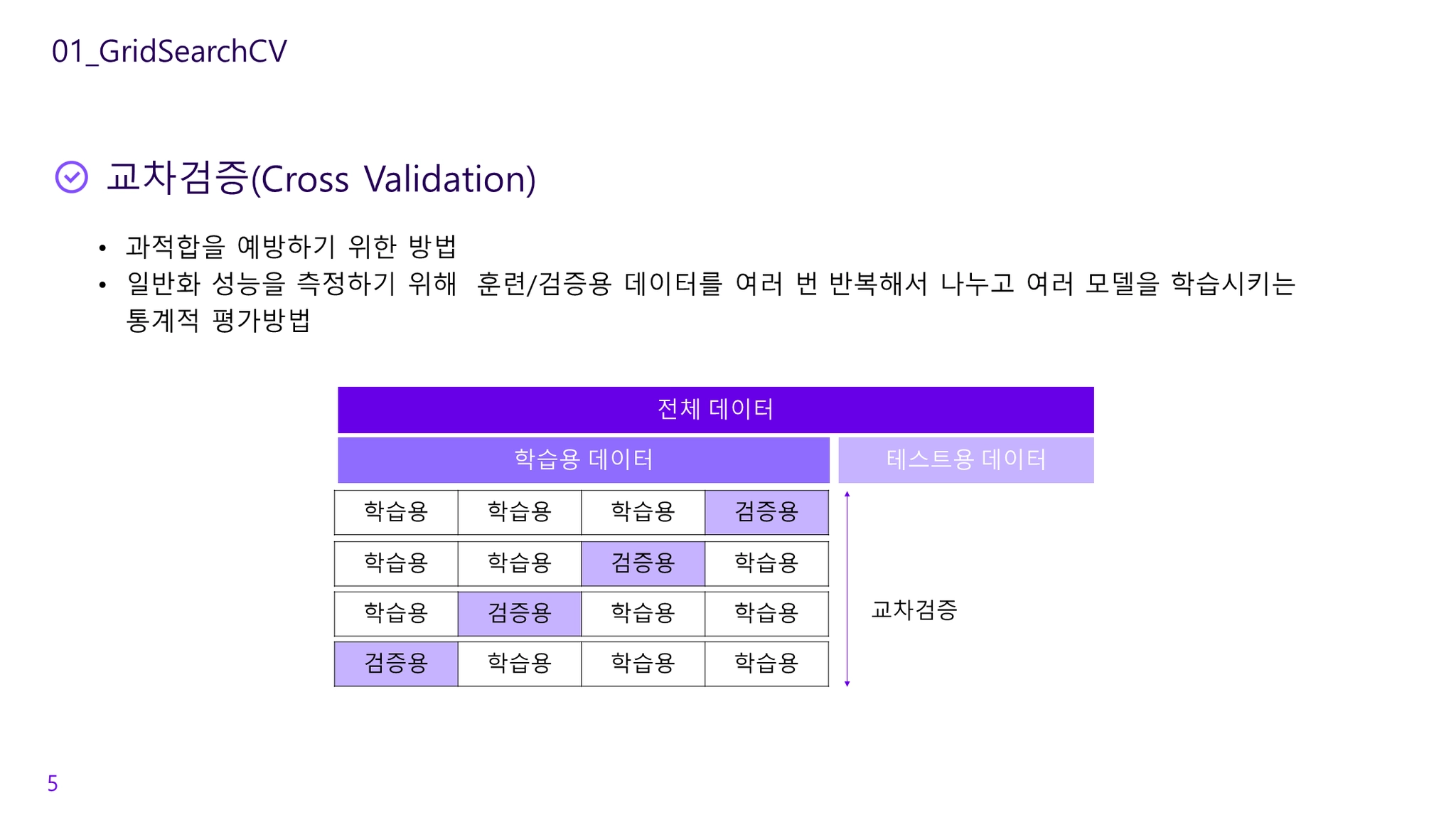
Cross Validation(교차검증)
•
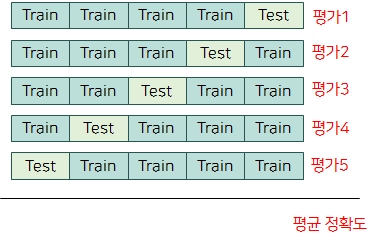
일반화 성능을 측정하기 위해 훈련/테스트 데이터를 여러 번 반복해서 나누고 여러 모델을 학습시키는 통계적 평가방법
•
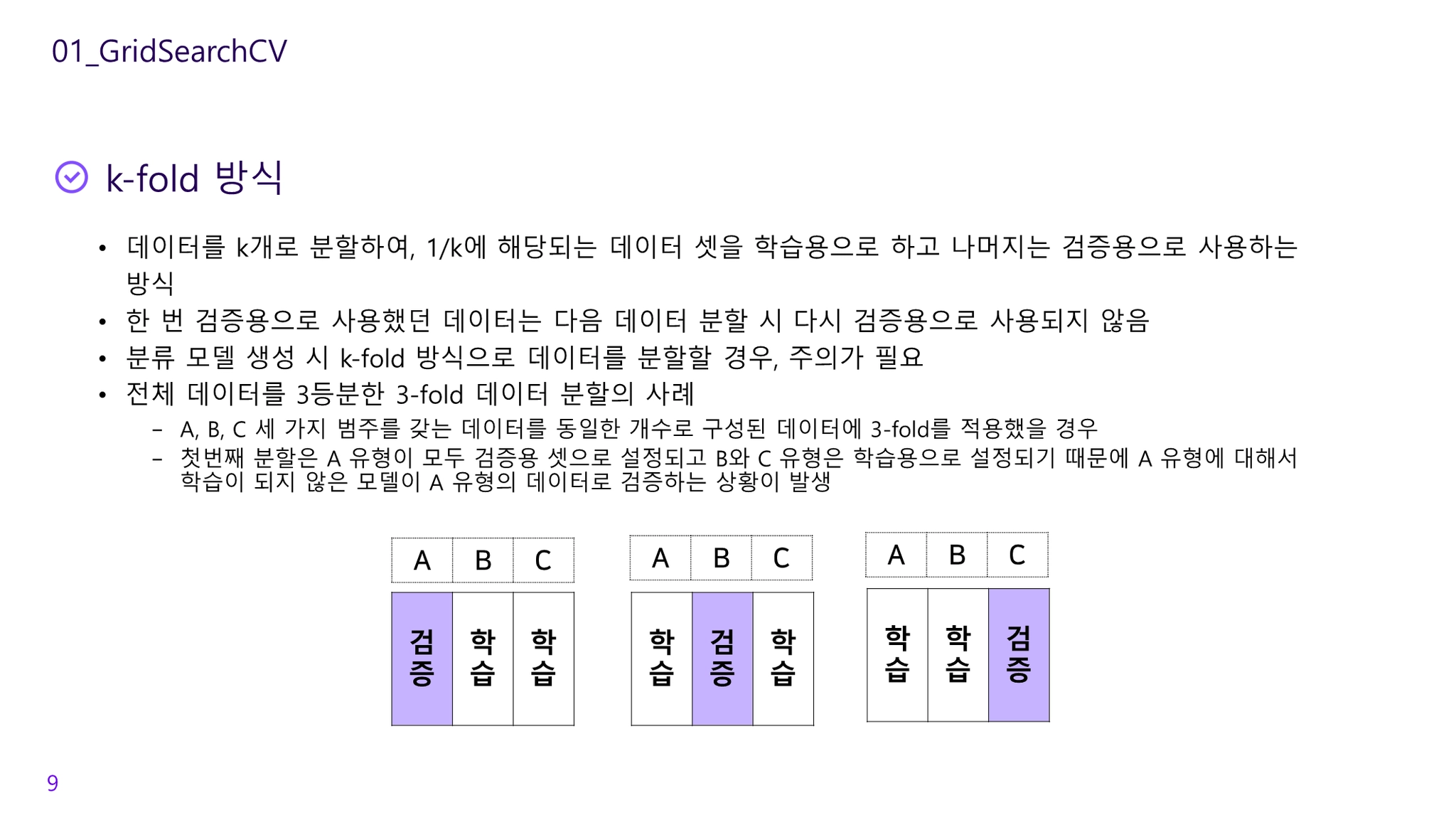
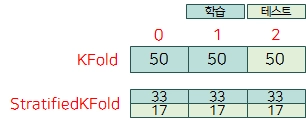
k-fold cross-validation
◦
데이터를 여러 번 반복해서 나누고 여러 모델을 학습
◦
•
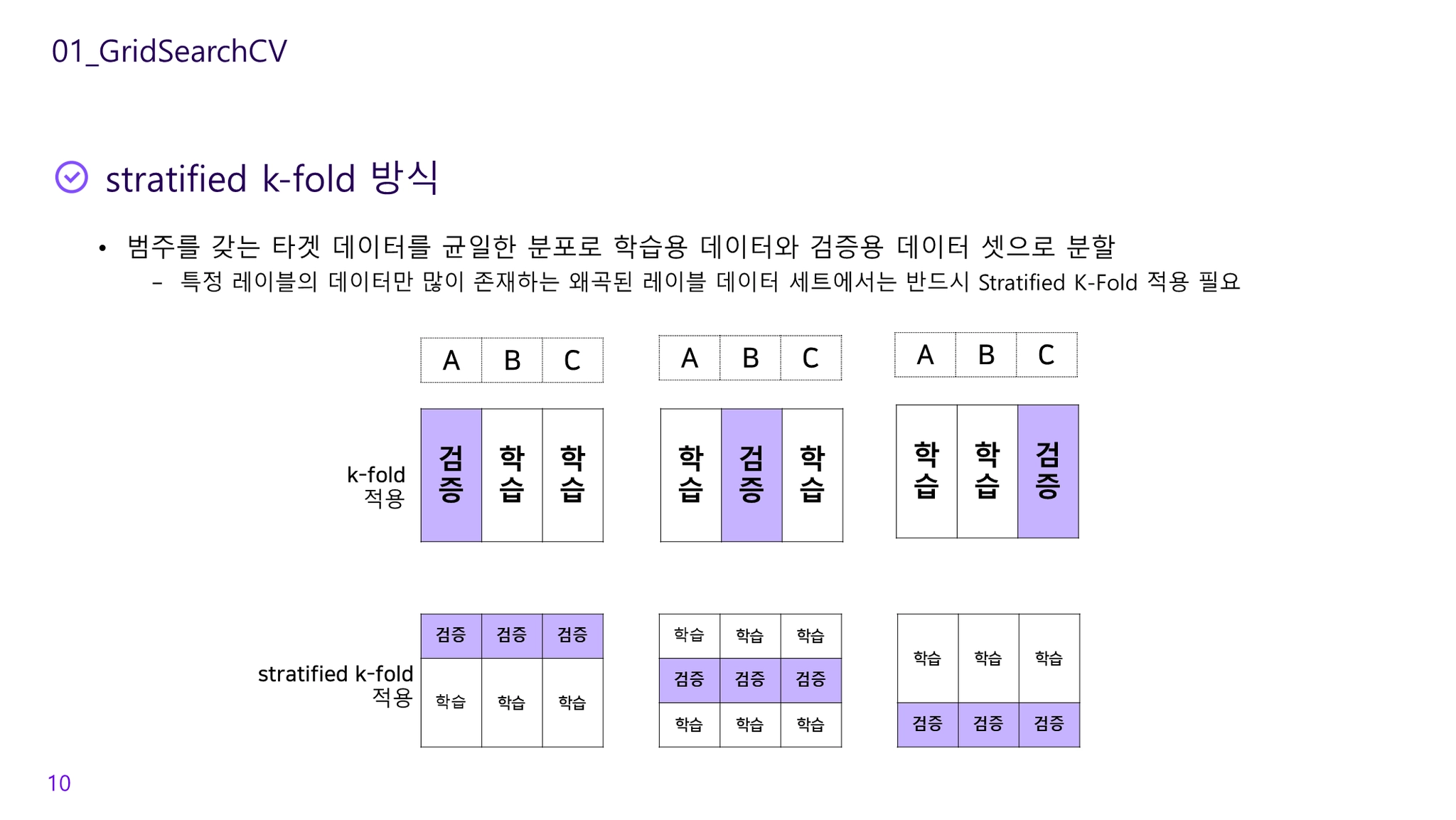
stratified k-fold cross-validation
◦
폴드 안의 클래스 비율이 데이터셋의 클래스 비율과 같도록 데이터를 나눔
◦
레이블 데이터를 균일한 분포로 학습/검증 데이터 셋으로 분할
◦
왜곡된 레이블 데이터 세트에서는 반드시 StratifiedKFold를 사용해야함
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_validate
scores = cross_validate(model, X, y, cv=3,
return_train_score=True, return_estimator=True)
scores
Python
복사