

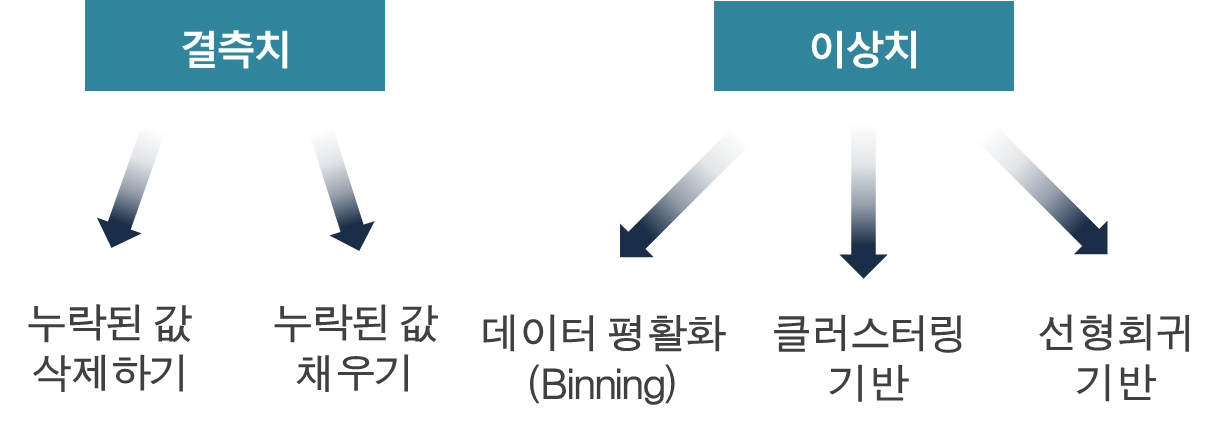
데이터 정제(Data Cleansing)
•
원본 데이터에 포함된 누락된 요소와 관련 없는 요소를 처리하는 활동
•
결측치 처리, 이상치 처리
결측치란?
•
데이터 수집 문제 또는 데이터 입력 오류와 같은 다양한 이유로 관측 되어야 할 값을 얻지 못한 데이터
•
전처리 단계에서 적절한 값으로 처리가 필요한 데이터

결측치가 포함된 데이터의 문제점
•
누락된 데이터 세트에 따라 특정 값으로 편향될 수 있음
•
일부 기계학습 알고리즘은 결측치가 포함된 데이터가 있을 경우, 학습이 불가능함
결측치 처리
① 결측치 포함 여부 확인하기
•
각 컬럼 별 결측치 수 확인

② 왜 결측치가 발생했는지 생각하기
•
결측치 발생 원인에 따라 처리 방법을 달리해야 함
•
데이터 분석가의 도메인 지식 필요

③ 결측치 비율 확인하기
•
결측치 비율에 따라 처리 방법을 달리함

④ 결측치 처리하기
•
1) 삭제: 데이터 양이 많은 경우 적합
◦
분류 작업의 클래스 레이블 값이 누락된 경우에 적합
•
2) 수동으로 채우기
◦
해당 필드에 일반화하여 적용 가능한 값 또는 평균으로 채움
▪
예: 동일한 신용 위험 등급의 사용자들 평균 소득 값으로 대체
◦
베이지안 분류 또는 결정 트리와 같은 방법을 사용하여 값을 유추하는 방법을 사용하여 채움
•
3) 전역 상수를 사용하여 누락된 값 채우기
◦
특정 상수로 대체 (예: NULL, 알 수 없음, 0)
◦
머신러닝 진행 시, 특정 용어 (예: 알 수 없음)가 중요한 개념을 형성한다고 믿을 수 있기 때문에 문제 발생 할 수 있음
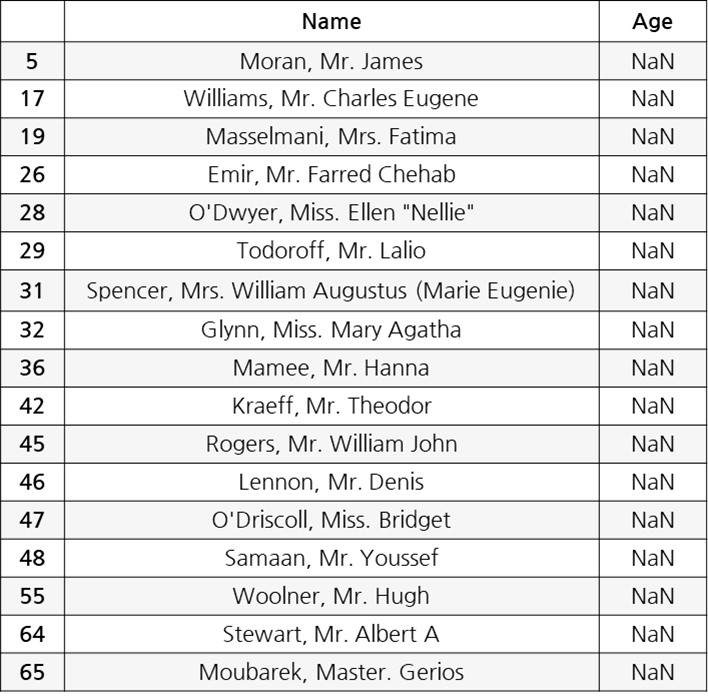
(예시)
Age 컬럼의 경우, Name 컬럼을 참조하여 유추하여 누락된 값을 채우는 방법 고려 가능

•
Age: 조건기반 대체
•
Cabin : column 삭제
•
Embarked : row 삭제
결측치 처리를 위한 파이썬 코드
import pandas as pd
from pandas import DataFrame, Series
import numpy as np
# 누락 값이 포함된 데이터를 읽어 DataFrame 객체 생성
concrete = pd.read_csv('concrete_na.csv’)
# 누락 값의 개수 확인
concrete.isnull().sum(0)
# 임의로 2번, 3번 행의 모든 데이터가 누락 값이 되도록 변경
concrete.iloc[2:4] = np.nan
# 누락 값이 모든 열에 있을 때 데이터를 버림
concrete.dropna(0, how='all', inplace=True)
# 누락 값을 특정 값으로 채움
concrete.fillna(100.)
# 누락 값을 평균 값으로 채움
concrete.fillna(concrete.mean(0))
Python
복사