


학습용 데이터와 테스트용 데이터

학습용 데이터(Training set)
•
인공지능 모델을 학습시기키 위해 필요한 데이터 셋
•
경우에 따라 학습용 데이터 일부를 검증용 데이터로 활용
테스트용 데이터(Testing Set)
•
학습이 완료된 모델의 정확도를 판단하기 위한 테스트 셋
검증용 데이터(Validation Set)
•
인공지능 모델에 사용되는 하이퍼파라미터*를 최적화하기 위해 사용하는 데이터 셋
◦
하이퍼파라미터: 머신러닝 알고리즘별로 최적의 학습을 위해 사람이 직접 입력하는 파라미터
◦
데이터 분할
•
•
Parameter

•
Return

•
예제
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
Python
복사
Hold-out(예비법)
전체 데이터를 서로 겹치지 않는 두 데이터 집합으로 비복원 추출(예: 70% 훈련용, 30% 시험용)

Bootstrap(부트스트랩)
•
데이터를 랜덤으로 샘플링하여 복원 추출하는 방식
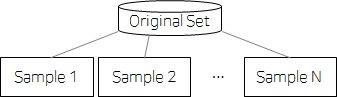
•
복원추출: 한 표본에 같은 데이터가 여러 번 추출될 수도 있고, 어떤 데이터는 추출되지 않을 수도 있음
•
앙상블의 배깅(Bagging, Bootstrap Aggregating) 방식에서 사용
◦
주어진 데이터를 반복적을 성과를 측정하여 그 결과를 평균하는 분류분석 모형을 평가하는 방법