


데이터 통합이란?
•
다양한 이기종 데이터 소스의 데이터를 일관된 데이터 저장소로 결합하는 기술
•
데이터 통합의 필요성
◦
최종 데이터 세트의 불일치 및 중복을 피하고 줄이는 데 도움
◦
데이터 마이닝 프로세스의 속도와 정확성을 개선하는 데 도움

데이터 통합 방법
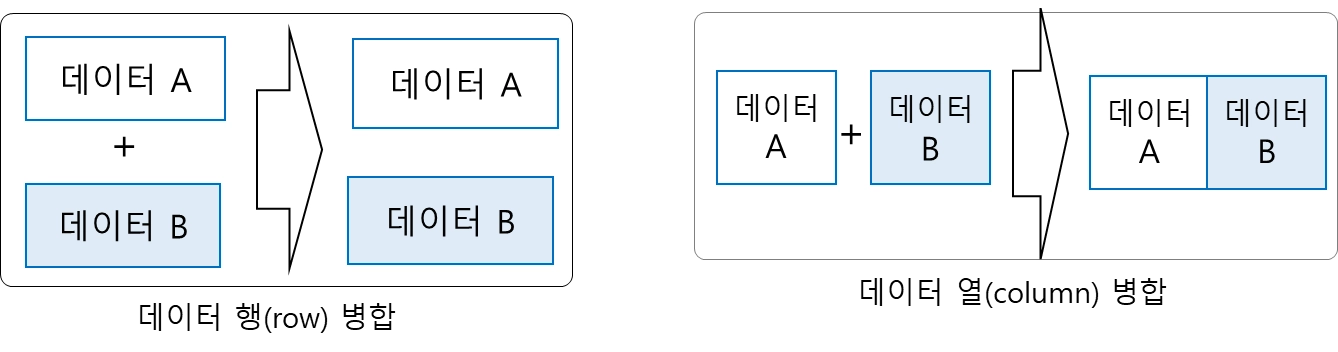
데이터 병합과 데이터 조인
데이터 병합
•
“이어 붙이기”
•
여러 개의 데이터 파일이 있는 경우, column(열)을 결합하거나 row(행)을 결합하는 작업
•
예시
◦
기업의 상반기 데이터 A와 하반기 데이터 B가 다른 파일에 저장된 경우, 데이터 A와 데이터 B를 병합하여 분석
▪
전제 조건: 데이터 A와 데이터 B는 같은 컬럼을 사용함
◦
학생의 국어성적 데이터 A와 수학성적 데이터 B가 다른 파일에 저장된 경우, 데이터 A와 데이터 B를 병합하여 분석
▪
전제 조건: 데이터 A와 데이터 B에서 동일한 인덱스를 갖는 데이터는 같은 인스턴스를 의미할 경우
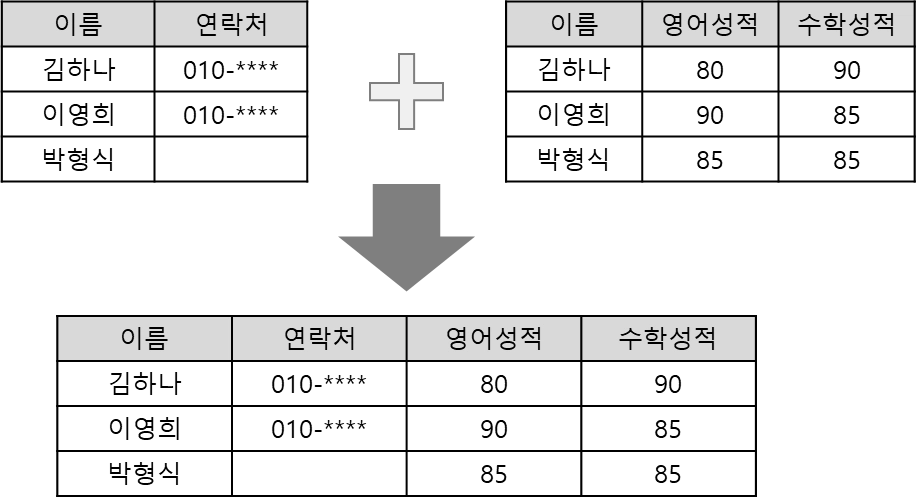
데이터 조인
•
“기준을 두고 합치기”
•
설정한 key값을 기준으로 두 개의 데이터 셋을 결합하는 방법
•
예시
◦
학생 기본 정보 데이터 A와 성적 정보 데이터 B가 다른 파일에 저장된 경우, 데이터 A와 데이터 B를 조인하여 분석
조인 방법 | 설명 |
Inner join | -가장 보편적으로 사용하는 방법으로, key(키)를 기준으로 두 테이블에 같이 존재하는 데이터를 추출 |
left outer join | -왼쪽 데이터셋에 있는 테이블의 key를 기준으로 병합 |
right outer join | -오른쪽 데이터셋에 있는 테이블의 key를 기준으로 병합 |
full outer join | -key를 기준으로 두 테이블에 존재하는 모든 데이터를 뽑아내어 병합 |
Inner join
key(키)를 기준으로 두 테이블에 같이 존재하는 데이터를 추출(교집합)
•
예제 : '이름'을 key로 하여 Inner join 수행
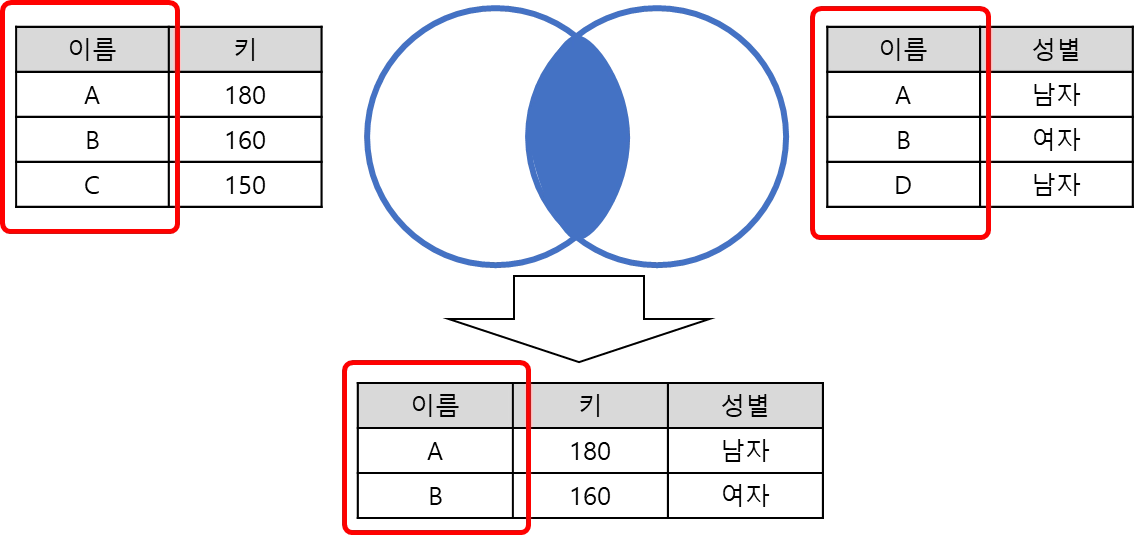
inner join
Left outer join
왼쪽 데이터셋에 있는 테이블의 key를 기준으로 병합
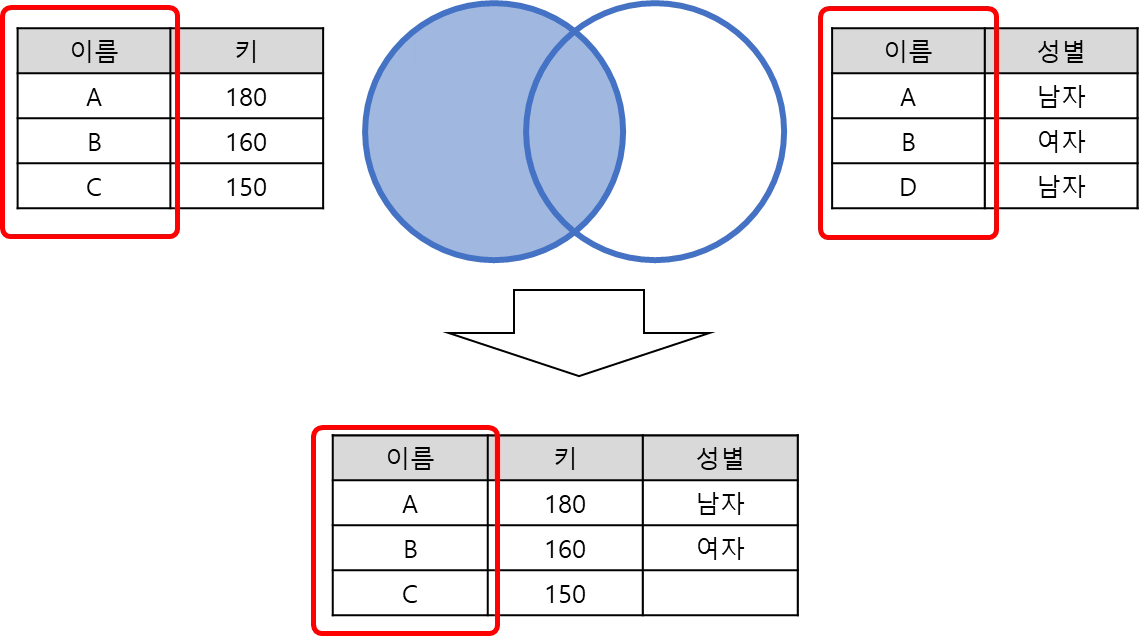
left join
Right outer join
오른쪽 데이터셋에 있는 테이블의 key를 기준으로 병합
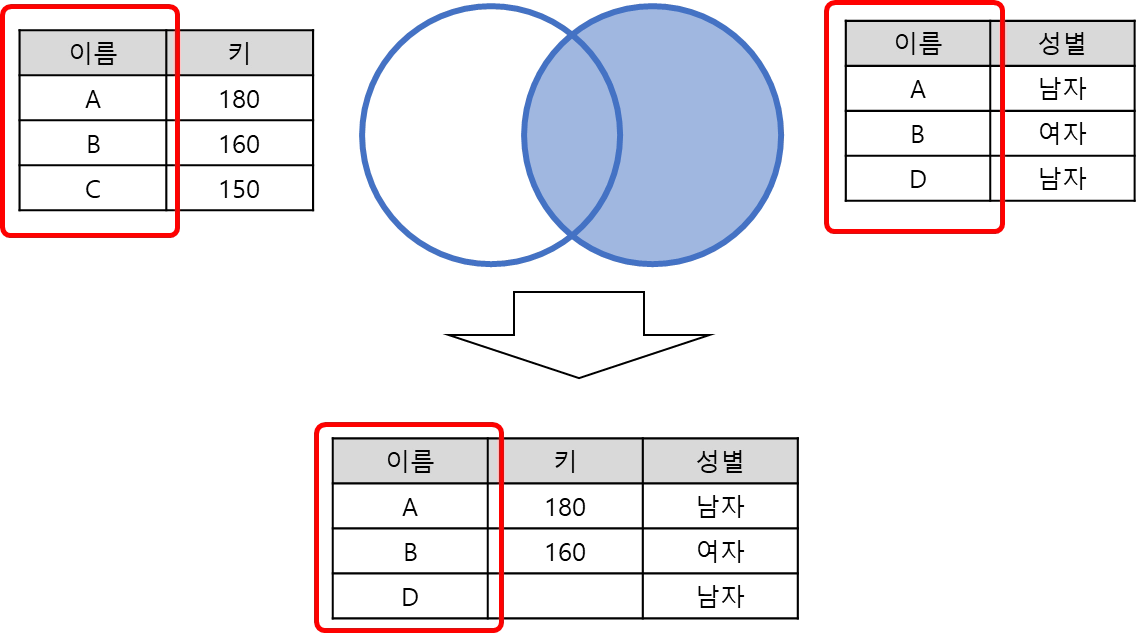
right join
Full outer join
key를 기준으로 두 테이블에 존재하는 모든 데이터를 뽑아내어 병합
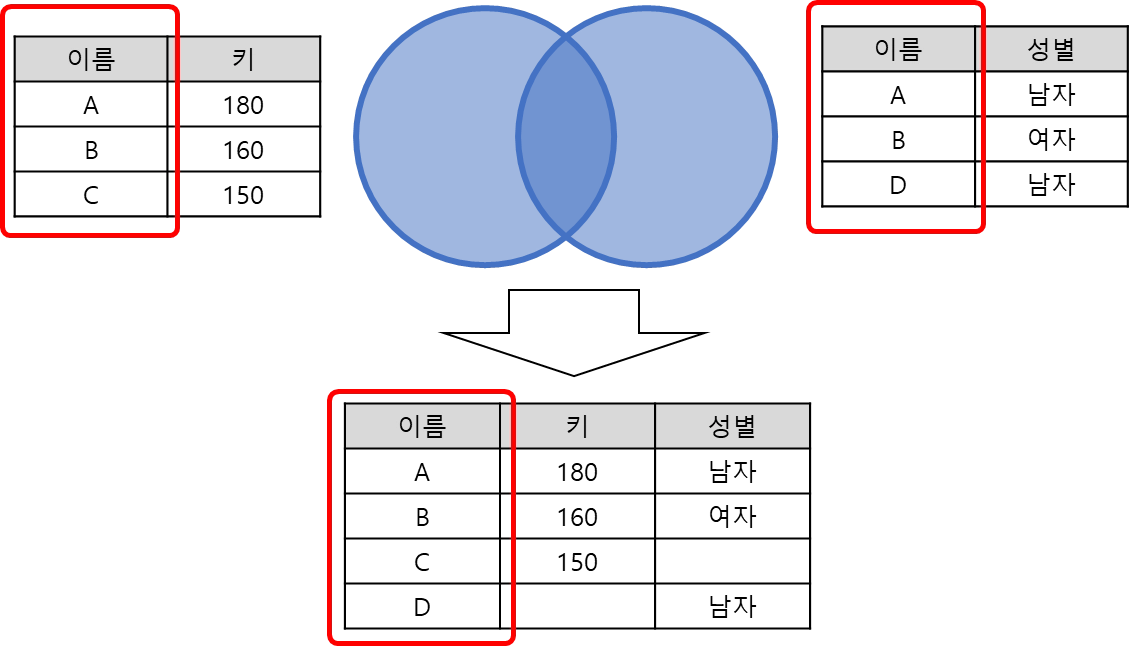
outer join
데이터 통합 과제
•
이기종 데이터 소스의 데이터를 일관된 데이터 저장소로 결합하기 위해서, ① 공통코드 관리와 ②중복 데이터 처리가 필요함
과 제 | 설 명 |
통합 스키마 | - 글로벌 스키마(메타데이터 통합)
- 예) '장비’ – (컴퓨터, 복사기 등) vs (에어컨, 냉장고 등) |
의미적 이질성 | - 동음 이의어(같은 단어에 대한 다른 의미)
- 예) 'Title’ - 'Person Title' vs 'Job Title' |
레코드 복제
| - 중복되는 데이터에 대한 불일치 발생
- 예) ‘주문’ 데이터베이스: ‘이름’, ‘주소’
‘구매자’ 데이터베이스: ‘이름‘, ‘주소’
→ 같은 ‘이름’, 다른 ‘주소’ |
데이터 값 충돌
(다른 표현 또는 척도 등) | - 인코딩, 단위, 표현의 차이 때문에 발생
- 메타데이터에 데이터 형식, 의미, 이름, 속성값의 허용 범위, 널 허용 여부, 빈 값 처리 규칙 등을 정의
- 예) 무게: 파운드(lb), 킬로그램(kg) |
데이터 통합 과정
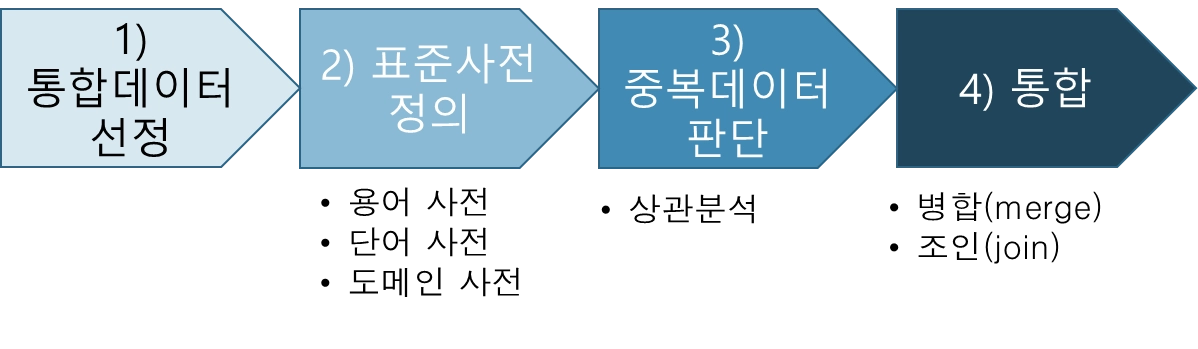
데이터 통합 과정 프로세스
표준 사전 정의
공통표준용어, 단어, 도메인 사전 정의 사례(공공데이터 공통표준)
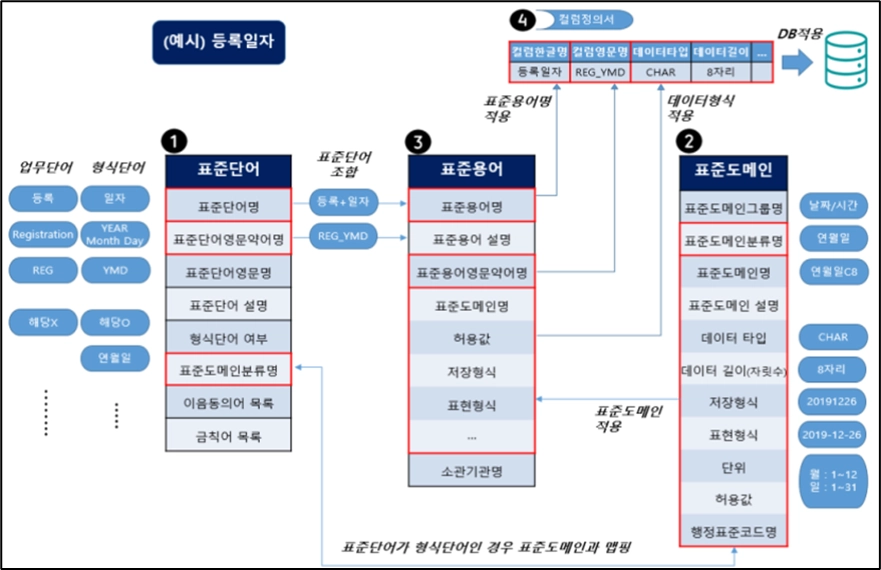
[출처] 공공데이터 포털 – 공공데이터 공통표준용어
•
공통 표준 도메인

•
공통 표준 단어

•
공통 표준 용어
