



목표
•
데이터 분석 프로젝트의 전체 과정에 대해 이해한다.
•
데이터 분석 프로젝트를 작성한다.
•
데이터 전처리 과정, 데이터 시각화, 데이터 분석 모델 생성에 대해 이해한다.
•
Github를 사용한 소스코드 관리 방법 및 프로젝트 최종 산출물 작성에 대해 이해한다.
데이터 셋
e-커머스(월마트) 판매 데이터 세트
월마트는 경쟁력 있는 가격으로 다양한 제품을 제공하고 전 세계 수백만 명의 고객에게 편리한 쇼핑 경험을 제공하는 것으로 유명한 전 세계적으로 인정받는 대형 유통업체입니다.
이 데이터 세트를 분석하면 월마트의 고객 기반과 구매 행동에 대한 귀중한 통찰력을 얻을 수 있습니다. 고객 인구 통계, 제품 선호도 및 지출 패턴에 대한 세부 정보가 드러납니다. 이 포괄적인 데이터 세트는 마케팅 전략, 고객 세분화 및 제품 수요와 같은 월마트 운영의 다양한 측면을 이해하는 데 귀중한 리소스입니다. 재고 관리, 타겟 마케팅 및 고객 관계 관리와 같은 분야에서 전략적 의사 결정을 향상시킬 수 있습니다.
1.
User_ID: 사용자 ID
2.
Product_ID: 제품 ID
3.
Gender: 사용자의 성별
4.
Age: 빈에 표시된 연령
5.
Occupation: 직업(마스킹 적용)
6.
City_Category: 도시의 카테고리 (A,B,C)
7.
StayInCurrentCityYears: 현재 도시에 머무른 연수
8.
Marital_Status: 결혼 상태
9.
ProductCategory: 제품 카테고리(마스킹 적용)
10.
Purchase: 구매금액
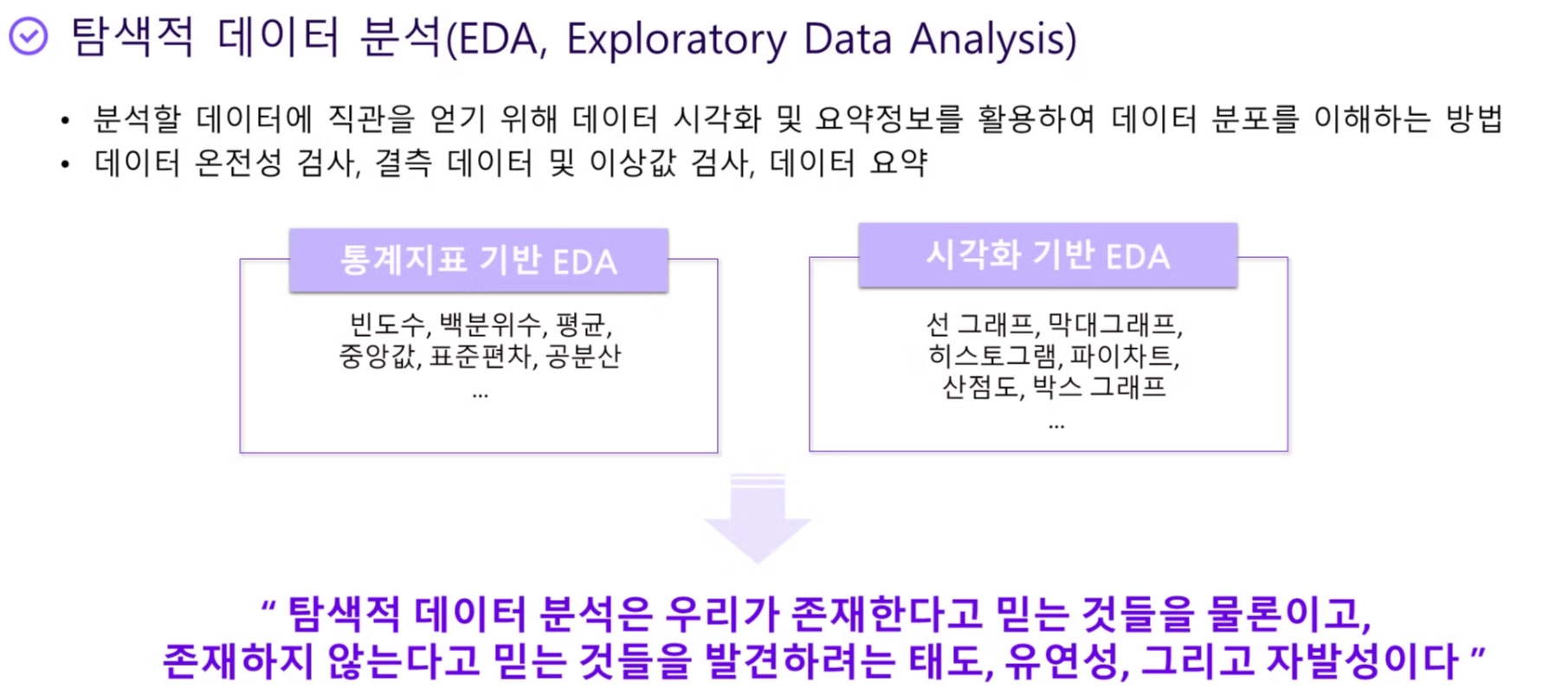
EDA
머신러닝 모델 학습 및 평가
데이터를 훈련용 데이터셋과 테스트용 데이터셋으로 분할하세요. train_test_split을 사용하고, 분할 비율과 랜덤 시드를 지정하여 그 이유를 설명하세요.
선형 회귀 모델 학습
수치형 목표 변수를 예측하기 위해 선형 회귀 모델을 학습시키세요. 학습한 모델의 계수를 해석하고, 예측 성능을 평가하세요.
분류 모델 학습
범주형 목표 변수를 예측하기 위해 로지스틱 회귀 또는 의사결정 나무 모델을 학습시키세요. 학습한 모델의 혼동 행렬(Confusion Matrix)을 작성하고, 정확도, 정밀도, 재현율을 계산하세요.
모델 성능 개선
하이퍼파라미터 튜닝
그리드 서치를 사용하여 모델의 하이퍼파라미터를 튜닝하세요. 최적의 하이퍼파라미터를 찾는 과정을 설명하고, 튜닝 전후의 모델 성능을 비교하세요.
특성 중요도 분석
학습한 모델에서 어떤 특성이 가장 중요한지 분석하세요. 특성 중요도(Feature Importance)를 시각화하고, 중요한 특성들이 모델 성능에 어떤 영향을 주는지 설명하세요.